Analýza dynamiky a struktury peněžních příjmů obyvatel Republiky Bashkortostan. Produktivita práce: pracujte chytře, až do noci
Při analýze tabulky lze dojít k závěru, že aktiva podniku klesla o 32 830 tisíc rublů, tj. O 0,2%. Je to především kvůli poklesu výsledků výzkumu a vývoje o 1 083 tis. rublů nebo 68,5%, jakož i snížení pohledávek o 42,3%.
Majetek podniku na konci analyzovaného období (2012) v peněžním vyjádření činil 14 195 053 tis. Rublů, včetně:
mimo oběžná aktiva - 6990389 tisíc rublů, což je 49,2% z celkové hodnoty nemovitosti;
oběžná aktiva - 7 205 654 tis. rublů, což je 50,7% z celkové hodnoty nemovitosti.
Analýza nehmotného majetku odhalila, že jeho absolutní a relativní hodnoty neustále rostou.
Analýza výsledků výzkumu a vývoje odhalila, že její absolutní hodnoty klesají. V roce 2011 došlo k prudkému poklesu ukazatelů na 71 tisíc rublů, což je o 1510 tisíc rublů méně než v roce 2010. Na konci analyzovaného období činil tento ukazatel 498 tis. Rublů, což rovněž ukazuje pokles ve srovnání s rokem 2010. Ve srovnání s rokem 2011 se však tento počet zvýšil. Tento pokles naznačuje, že výdaje na výsledky výzkumu a vývoje prudce klesají, což naznačuje špatné řízení.
Náklady na dlouhodobý majetek se v průběhu analyzovaného období zvyšují v souvislosti s nákupem zařízení. Ostatní dlouhodobá aktiva se během analyzovaného období také zvyšují.
Rezervy podniku v roce 2010 činily 399283 tis. rublů a činily 2,7% všech aktiv, do konce roku 2012 se zvýšily na 828 274 tis. rublů a činily 5,8% všech aktiv podniku.
Míra růstu daně z přidané hodnoty vykazuje nárůst o 232,2%, což naznačuje zvýšení objemu prodejů, a to také ukazuje zvýšení obratu samotného podniku.
Společnost má tendenci snižovat pohledávky - od roku 2010 do roku 2012 se snížila o 519 891 tis. Rublů, tj. O 42,3% a činila 5% všech aktiv společnosti.
Hotovost ve sledovaném období klesla o 764 tis. Rublů, tj. 23,5% a činila 0,02% aktiv podniku.
Ostatní oběžná aktiva, včetně položek s nízkou hodnotou a opotřebení, ve sledovaném období nepodstoupila změny.
Osady na farmě se v roce 2011 oproti roku 2010 snížily o 175 900 tisíc rublů. Na konci analyzovaného období se tento ukazatel oproti roku 2011 zvýšil o 1804457 tis. Rublů, což naznačuje nárůst vypořádání s dceřinými, přidruženými a mateřskými podniky.
Ve sledovaném období dochází ke zvýšení pasiv. V roce 2010 společnost vlastnila zdroje majetku ve výši 7289 tis. Rublů a do konce roku 2012 se tato částka zvýšila na 8810 tis. Rublů, tj. O 1521 tis. Rublů nebo 20,86%. Důvodem je zejména zvýšení podílu nerozděleného zisku ve struktuře závazků společnosti. Nerozdělený zisk se zvýšil z 3 772 tis. RUB v roce 2010 na 4 899 tis. RUB v roce 2012, tj. O 1 127 tis. RUB, což je o 29,88%.
Pojďme provést vertikální a horizontální analýzu závazků podniku NGDU „Elkhovneft“. Jako údaje pro vertikální a horizontální analýzu závazků společnosti uvedené v tabulce 2.2.3. Se používají hodnoty položek prezentovaných v rozvaze NGDU „Elkhovneft“.
Mezinárodní letecký osobní trh
Pro světový letecký průmysl byl rok 2016 celkem úspěšný: podle IATA byl nárůst obratu cestujících ve světě oproti roku 2015 5,9%. Objem osobní dopravy pravidelné lety vzrostly o 5,7% na 3,8 miliardy cestujících. Procento obsazenosti sedadel pro cestující v globálním průmyslu podle předběžných odhadů činilo 80,2%, což je 0,2 pb. pod výsledkem roku 2015.
V roce 2016 nejdynamičtěji se rozvíjející doprava na Středním východě. Růst obratu cestujících byl ve srovnání s rokem 2015 10,8%.
Druhé místo z hlediska míry růstu zaujímá trh v asijsko-tichomořském regionu, kde se obrat cestujících zvýšil o 8,9%.
V evropském regionu se osobní doprava zvýšila o 3,8%. Hlavním tahounem evropského trhu byl růst mezinárodní dopravy. Tato dynamika je způsobena zvýšením nosnosti o 3,8%, jakož i poklesem ziskových sazeb v důsledku vývoje segmentu rozpočtové dopravy a snížením nákladů na palivo.
Severoamerický trh vykázal 3,2% nárůst osobní dopravy, který byl způsoben silným ekonomickým růstem ve Spojených státech amerických a pozitivní dynamikou domácí dopravy.
Podle IATA se tržby v průmyslu meziročně snížily o 2,4% na 701 miliard USD. Většinu z nich tvořily tradičně příjmy z osobní dopravy - 71,9%. Pokles příjmů byl způsoben snížením nákladů na pohonné hmoty, což leteckým společnostem umožnilo snížit sazby příjmů bez snížení ziskovosti.
Podle předběžných odhadů IATA je čistý zisk odvětví za rok 2016 35,6 miliard USD, což je nejvyšší ukazatel v tomto odvětví za posledních deset let.
Osobní doprava na pravidelných letech po celém světě
Miliony lidí
Miliony lidí "title \u003d" (! LANG: Dynamika osobní dopravy na pravidelných letech globálního průmyslu Miliony lidí"> !}
Míra růstu obratu cestujících a maximálního obratu cestujících v globálním průmyslu
Poznámka. Drobné odchylky ve výpočtu procentuální změny, mezisoučty a součty na grafech v této výroční zprávě jsou zaokrouhleny.Ruský trh osobní letecké dopravy
V roce 2016 se celkový objem ruského trhu včetně zahraničních dopravců v porovnání s rokem 2015 snížil o 4,1% a činil 102,8 milionu cestujících. Ruské letecké společnosti přepravily zejména 88,6 milionů cestujících, což je o 3,8% méně než v předchozím roce. Obrat cestujících ruských leteckých dopravců se snížil o 5,0% a dosáhl 215,6 miliard osobokilometrů (rpm). Současně se objem přepravní kapacity snížil o 6,6% na 265,8 miliardy kilometrů (km), v důsledku čehož se procento obsazenosti sedadel pro cestující ruských leteckých společností zvýšilo o 1,4 procentního bodu na 81,1%.
Ve sledovaném období na konci roku 2015 nadále působily faktory, jako je snížení kupní síly obyvatelstva způsobené oslabením národní měny, omezení letů do Turecka, Egypta a Ukrajiny a odpovídající pokles prodejů na odchozím trhu cestovního ruchu.
Tyto faktory určovaly úbytek v turistickém (charterovém) segmentu. Podle TCH se objem charterové osobní dopravy v roce 2016 oproti předchozímu roku snížil o 27,0%, včetně mezinárodní charterové dopravy o 39,8%. V důsledku toho se počet cestujících přepravených na mezinárodních trasách (včetně dopravy prováděné zahraničními leteckými společnostmi) v roce 2016 snížil o 15,1% ve srovnání s rokem 2015 a činil 46,4 milionu lidí.
Segment domácí dopravy si udržel pozitivní dynamiku: počet cestujících vzrostl o 7,3% ve srovnání s předchozím rokem a činil 56,4 milionu lidí, což je způsobeno rozvojem domácího cestovního ruchu, včetně změny orientace odchozích turistických toků. Průměrná obsazenost sedadel cestujících na domácích trasách činila 79,5%, což je 2,9 procentního bodu. vyšší než v roce 2015.
Osobní doprava na ruském trhu (včetně zahraničních leteckých společností)
Miliony lidí
title \u003d "(! LANG: Osobní doprava na ruském trhu (včetně zahraničních leteckých společností) Miliony lidí">!}
Zdroj: TKP, Federal Air Transport Agency
Osobní doprava na ruském trhu (kromě zahraničních leteckých společností)
Miliony lidí
title \u003d "(! LANG: Osobní doprava na ruském trhu (kromě zahraničních leteckých společností) Miliony lidí">!}
Zdroj: Federální agentura pro leteckou dopravu
Obrat cestujících na ruském trhu (kromě zahraničních leteckých společností)
BLN PKM
title \u003d "(! LANG: Osobní doprava na ruském trhu (kromě zahraničních leteckých společností) BLN PKM
!}">
Zdroj: Federální agentura pro leteckou dopravu
Maximální osobní provoz na ruském trhu (kromě zahraničních leteckých společností)
BILLION KKM
title \u003d "(! LANG: Maximální osobní provoz na ruském trhu (kromě zahraničních leteckých společností) BILLION KKM">!}
Zdroj: Federální agentura pro leteckou dopravu
Dynamika procenta obsazenosti sedadel cestujících na ruském trhu (kromě zahraničních leteckých společností)
%
V průběhu roku 2016 objem letecké dopravy na ruském trhu klesal, ve čtvrtém čtvrtletí se však zastavil a osobní doprava se ve srovnání s předchozím rokem zvýšila o 10,6%. Změna trendu je spojena s účinkem nízké srovnávací základny, se oslabením negativních faktorů ovlivňujících rozvoj letecké dopravy (včetně stabilizace směnného kurzu) a korekcí ziskových sazeb v průmyslu, které spolu s naznačeným účinkem směnného kurzu určily snížení nákladů na rubl cestujících pro cestující.
Skupina Aeroflot je jedním z klíčových růstových faktorů ruského trhu letecké dopravy, který zajišťuje dopravní dostupnost a mobilitu obyvatelstva. Bez zohlednění pozitivní dynamiky osobní dopravy skupiny Aeroflot se trh oproti roku 2015 snížil o 12,5%.
Dynamika tempa růstu 1 osobní dopravy ruských a zahraničních leteckých společností v roce 2016
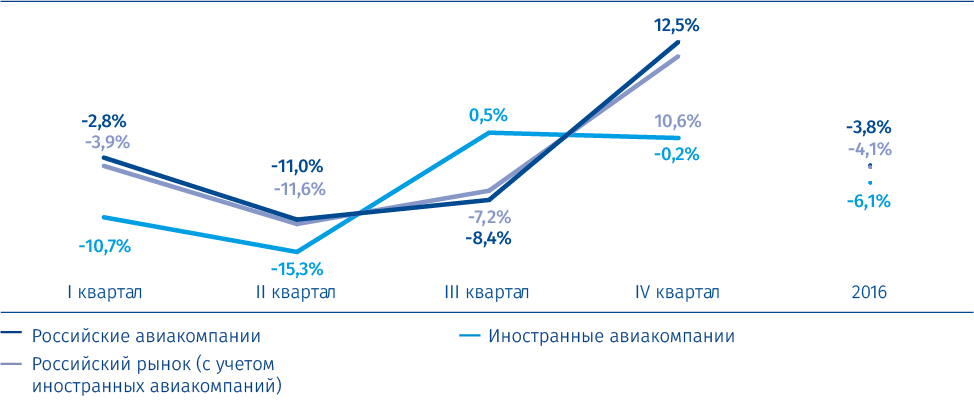
Zdroj: TKP, Federal Air Transport Agency
Dynamika tempa růstu 1 osobní dopravy skupiny Aeroflot a ruského trhu v roce 2016
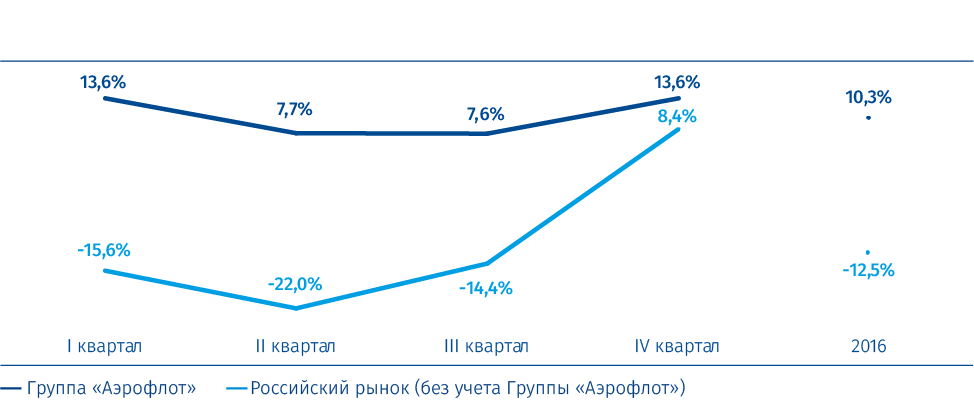
Zdroj: TKP, Federal Air Transport Agency
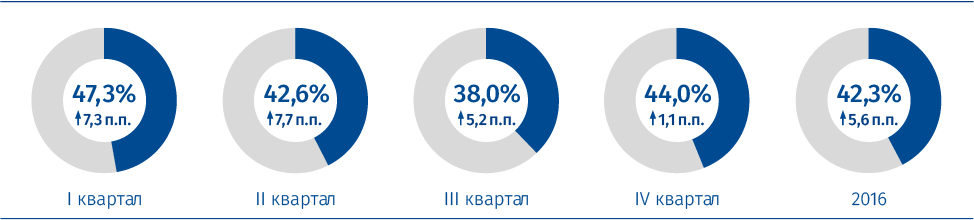
Zdroj: TKP, Federal Air Transport Agency
1 Ve srovnání se stejným obdobím předchozího roku.Ruský trh letecké dopravy je vysoce konsolidovaný - pět největších hráčů představuje 70,4% osobní dopravy. Aeroflot Group je na tomto trhu nesporným lídrem. Na konci roku 2016 činil podíl skupiny Aeroflot 42,3% z celkového provozu na ruském trhu, včetně přepravy zahraničními leteckými společnostmi (36,7% v roce 2015). Během sledovaného období bylo zaznamenáno zvýšení tržního podílu skupiny Aeroflot, přičemž největší nárůst byl zaznamenán v prvním a druhém čtvrtletí.
Růst tržního podílu skupiny Aeroflot je zajištěn efektivním obchodním modelem a strategií, která určila odolnost skupiny vůči vnějším ekonomickým a tržním faktorům. Nárůst podílu skupiny je také spojen s přerozdělováním akcií Transaero Airlines (ukončení provozu v říjnu 2015) a zahraničních dopravců, které snižují jejich přítomnost na ruském trhu. Další vliv na růst tržního podílu skupiny Aeroflot měl aktivita v segmentu mezinárodní tranzitní dopravy, zejména mezi Evropou a Asií. Bez mezinárodního tranzitu činil „čistý“ podíl skupiny Aeroflot v roce 2016 40,0%. Definice čistého trhu je správnějším odrazem podílu na trhu vzhledem k tomu, že cestující cestující mezi místy v Evropě a Asii s přestupem v Moskvě nesouvisí s ruským trhem a samotná skutečnost, že tyto cestující přilákají, má pozitivní ekonomický účinek nejen pro společnost, ale také pro ruskou ekonomiku jako celek.
Nejbližšími konkurenty Aeroflot Group jsou S7 Group (12,8%), UTair Group (6,8%), Ural Airlines (6,3%). Podíl zahraničních dopravců na ruském trhu byl 13,9%.
Dynamika podílu skupiny Aeroflot na ruském trhu, pokud jde o osobní dopravu, s přihlédnutím k zahraničním společnostem
| 2012 | 2013 | 2014 | 2015 | 2016 | |
| Mezinárodní letecké společnosti | 28,4% | 27,0% | 26,1% | 29,3% | 39,4% |
| Domácí letecké společnosti | 32,6% | 36,1% | 38,0% | 44,6% | 44,6% |
| Celkový | 30,0% | 30,5% | 31,0% | 36,8% | 42,3% |
V roce 1996 se podíl příjmů nejchudších 20% zvýšil asi o 1%, mírně se zlepšila situace druhé a třetí skupiny s nízkými a středními příjmy. Naopak podíl příjmů 20% nejbohatší skupiny obyvatelstva se snížil o 2%. Nakonec se podíl příjmů nejbohatší 10% skupiny zvýšil o 3%.
Obecně jsou údaje uváděné Goskomstatem poněkud protichůdné a neumožňují učinit určité závěry o přítomnosti významných změn v rozdělení příjmů obyvatelstva. Pozornost se tak upozorňuje na nárůst mezery v příjmech mezi nejbohatšími a druhými z hlediska příjmů 10% populace - tento rozdíl byl přibližně dvakrát v roce 1995 a v roce 1996 - již 3,17krát. Zároveň by se v této situaci mělo zvýšit nerovnoměrné rozdělení příjmů. Na druhé straně druhá skupina 10% obdržela v roce 1996 pouze 10,7% všech příjmů (oproti 15,9% v roce 1995), zatímco druhá skupina 20% představovala 22,4% příjmů. Jinými slovy, v údajích uváděných Goskomstatem jsou nesrovnalosti (čistě statisticky je takový poměr příjmů „bohatší“ 10% skupiny a další 20% skupiny bezprostředně po jejím zaregistrování). Podle Goskomstatu byl také zaznamenán nárůst mezery v příjmech mezi první a druhou desetiprocentní skupinou - z 1,4krát v roce 1995 na 1,5krát v roce 1996.
V roce 1996 zůstala úroveň meziregionální diferenciace příjmů obyvatelstva extrémně vysoká. Rozdíl mezi průměrnými příjmy na hlavu registrovanými v Moskvě a příjmy na hlavu v Rusku jako celku se zvětšil z 3,1krát v březnu 1995 na 3,4krát v září 1996. vzhledem k tomu, že v první polovině roku 1995 byly příjmy na hlavu v Moskvě nižší než příjmy, přijato v Magadánská oblast, pak na konci roku 1996 Moskevské příjmy překročily příjmy Magadanu více než dvakrát. Rozdíl mezi moskevskými příjmy a příjmy obyvatel jiných regionů Ruska tedy do značné míry vysvětluje konečné vysoké ukazatele charakterizující diferenciaci ruské populace podle úrovně příjmu. Určité snížení nerovnosti příjmů v takové situaci lze vysvětlit pouze trvalým poklesem intraregionálních ukazatelů diferenciace. V tomto případě se však Moskva stává výraznou „výjimkou z pravidla“ - podle Moskevského statistického výboru pro města se index Gini v posledních dvou letech na úrovni 0,55 - 0,6 - jinými slovy, Moskva předstihla Brazílii, pokud jde o nerovnost v příjmech. Moskevský fenomén je však částečně vysvětlen samotnou metodou sběru dat - kvůli vysoké koncentraci finančních a bankovních struktur a obchodních institucí v Moskvě je určitá část příjmů obyvatel jiných regionů, získaná zprostředkováním moskevských organizací, také zahrnuta do příjmů obyvatel Moskvy.
Hodnota životního minima (stanovená metodikou Ministerstva práce) činila ke konci roku 1996 379 tisíc rublů. za osobu. Poprvé bylo v průběhu roku zaznamenáno snížení životního minima - v prosinci bylo životní minimum pro všechny skupiny obyvatelstva mírně nižší než v červnu. Tato okolnost podle našeho názoru opět potvrzuje, že metoda výpočtu minima, kterou používají statistické úřady a která byla vyvinuta ministerstvem práce, je založena na příliš těsném navázání minimální velikosti na ceny základních potravinářských výrobků. Samotný sezónní pokles cen zeleniny může jen stěží stačit k závěru, že minimální spotřebitelský balíček je levnější (v září byly životní náklady v Rusku v průměru nižší než v červnu o 5–6%). Zachování stejné struktury výdajů v základním koši používaném pro výpočet životního minima - tedy se zaměřením na proporce rozdělení fondů charakteristických pro rodiny s nízkými příjmy na prahu 90. let - vede ke skutečnosti, že sledování hodnoty odpovídajícího ukazatele vypočtené podle metodiky Ministerstva práce se postupně stává formalizovaným statistickým cvičením.
Průměrné peněžní příjmy na hlavu 22% populace v roce 1996 byly pod minimem (v roce 1995 tato skupina zahrnovala 24,7% populace). Současně počet chudých v průběhu roku 1996 trvale klesal - z 24% v prvním čtvrtletí na 19 procent ve čtvrtém čtvrtletí roku 1996.
V roce 1996 došlo k mírnému zlepšení poměru mezi průměrnou úrovní peněžního příjmu a životním minimem - z 201% v roce 1995 na 211% v roce 1996.
V prosinci 1996 byl průměr mzda zvýšil na 944 tisíc rublů; nominální průměrný plat v roce 1996 jako celek činil asi 800 tisíc rublů. a vzrostl ve srovnání s 1,6krát 1995. Průměrná reálná mzda v reálném vyjádření (s přihlédnutím k indexu spotřebitelských cen) se v roce 1996 zvýšila o 5% a její poměr k životnímu minimu (pro obyvatelstvo v produktivním věku) se v průběhu roku 1996 zvýšil z 1,68 na 2,2krát. Nárůst nedoplatků na mzdách v roce 1996 činil více než 26 bilionů rublů. (asi 4% z celkové nashromážděné mzdy); Za těchto okolností zůstaly reálné mzdy v roce 1996 prakticky nezměněny. Měsíční dynamika průměrných nashromážděných mezd v národní ekonomice v roce 1996 je charakterizována údaji v tabulce 3.4.
Při celkové stabilizaci reálných mezd došlo k pomalému vyrovnávání mezd napříč odvětvími ekonomiky: například průměrná mzda ve zdravotnictví, tělesné výchově a sociálním zabezpečení ve srovnání s národním průměrem byla (podle údajů za leden až listopad 1996) 75% oproti 71% před rokem, ve veřejném vzdělávání se tento ukazatel zvýšil ze 63 na 68%, v kultuře a umění - z 58 na 63%, ve vědě a vědeckých službách - ze 75 na 81%. Na druhé straně se rozdíl mezi průměrnými mzdami mezi předními průmyslovými odvětvími a ekonomikou jako celku mírně zúžil: pokud byl v roce 1995 průměrný plat v produkci ropy 2,88krát vyšší než průměr v ekonomice, pak v roce 1996 byl 2,78krát hodnota pro plynárenství klesla z 3,98 na 3,83. Pouze v jednom odvětví - lehkém průmyslu - průměrná mzda v roce 1996 několikrát klesla pod životní minimum pro zdatnou populaci. V ekonomice jako celku průměrná mzda zhruba odpovídala životní úrovni rodiny dvou produktivních let.
Na své tradiční konferenci VOP 2017 minulý měsíc Nvidia tradičně představila novou výpočetní architekturu, dříve nazvanou Volta. Po mnoho let se společnost angažuje daleko od herního trhu GPU a úspěšně se podílí na dalších oblastech: profesionální grafická a výpočetní řešení, vysoce výkonné počítačové systémy a automobilové systémy.
Kromě toho finanční výkazy společnosti za několik čtvrtletí jasně ukazují, že ačkoli herní řešení zůstávají pro společnost Nvidia stále nejdůležitější a nejdůležitější, výnosy z dodávek v oblasti automobilových řešení a segmentu vysoce výkonných počítačových systémů (servery, datová centra atd.) Rostly v opakovaně. Není proto překvapivé, že společnost stále více investuje do vývoje řešení určených speciálně pro negrafické výpočty. Hráči mají z toho také určité výhody - pokud před několika lety to byli hlavně ti, kdo zaplatili za vylepšení GPU, nyní přidali zdravý podíl vážnějších aplikací.
Vysoce výkonný výpočetní systém se nyní zabývá především různými aplikacemi umělé inteligence. A tyto systémy touží po vícenásobném zvýšení výpočetní rychlosti každý rok. Neuronové sítě a další systémy umělé inteligence, kterým dříve chyběl výpočetní výkon, pronikají do stále většího rozsahu aplikací: autonomní řízení, rozpoznávání řeči a inteligentní vyhledávání, rozpoznávání a popis objektů, boj proti nemocem a stárnutí člověka a mnoho dalšího. Pokud vás zajímají praktické aplikace AI v současnosti i v budoucnosti, můžete si o tom přečíst v zpráva z konference GTC 2017.
Podle analytiků přinese vývoj technologií založených na umělé inteligenci za pět let odvětví několikanásobně vyšší příjem než v současnosti. A s největší pravděpodobností za pár let Nvidia vydělá více peněz z práce na počítači než ze zábavy. Proto v této oblasti nyní aktivně pracují a již mají na trhu dobré pozice s ještě větším potenciálem. Společnost Nvidia byla průkopníkem ve vysoce výkonných počítačích založených na procesorech dříve známých jako grafické procesory a přinášejí na trh skvělý hardware a software a zároveň udržují silné vztahy s vývojáři.
V tomto článku je pro nás obzvláště důležité, že Nvidia již má motivaci vytvářet samostatné GPU pro výpočetní techniku \u200b\u200ba oddělené GPU pro hry, jak to již nějakou dobu dělá. Přestože GPU Nvidia a výpočetní procesory stejné generace jsou architektonicky velmi blízké a v mnoha ohledech podobné, již mají důležité rozdíly, které jsou jedinečné pro specifické aplikace - pamatujte si pouze paměť HBM2 použitá v rodině výpočetních urychlovačů Pascal nebo výrazně větší počet bloků pro FP64 - výpočty.
Schopnosti a výkon moderních výpočetních systémů rostou a vývoj neuronových sítí pro ně nyní představuje zvláštní výzvy. Pokud to dříve bylo pro mnoho společností příliš drahé nebo dokonce nemožné, nyní si i malé společnosti mohou dovolit hluboké učení a neuronové sítě k řešení naléhavých problémů. Právě zrychlení hlubokých výukových úkolů si ponechalo svou stopu na nové výpočetní architektuře Volty, na kterou se dnes podrobněji podíváme.
Tesla V100 Computing Accelerator
Základem je vysoce výkonné počítačové zpracování (HPC) moderní věda a používají se v mnoha oblastech činnosti: předpovědi počasí, průzkum ropných a plynových polí, vývoj nových drog atd. - vědci používají vysoce výkonné počítačové systémy k simulaci světa kolem světa a předpovídání událostí v něm.
Umělá inteligence a neuronové sítě rozšiřují tradiční využití HPC pro analýzu velkého množství dat a pro rychlé trénování umělé inteligence a simulace nemohou vždy přesně předpovídat události ve skutečném světě. Řešení stále složitějších problémů umělé inteligence vyžaduje školení stále složitějších neuronových sítí, což na stávajících výpočetních systémech vyžaduje velmi dlouhou dobu. Složitost úkolů určených pro výpočet akcelerátorů neustále roste, každý rok vyžaduje vyšší výkon a samotné CPU se s tím již dlouho nedokázaly vyrovnat.
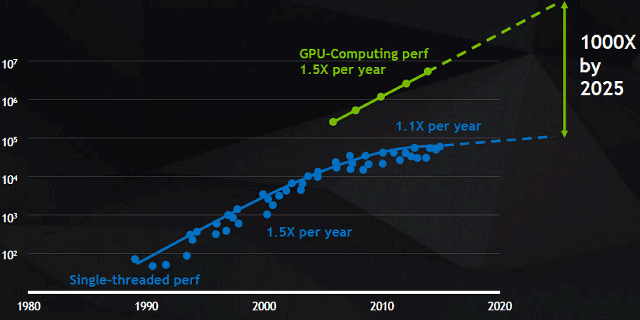
Průmysl HPC nyní dosahuje ještě většího skoku vpřed, než je obvyklé 1,5x ročně. Průmysl byl také ovlivněn vznikem specializovaných řešení strojového učení, jako je Google Tensor Processing Unit (TPU), jehož druhá verze byla nedávno ohlášena. Společnost Nvidia se proto rozhodla držet krok s prezentací nové generace výpočetní architektury Volta, která zahrnovala specializované bloky, které poskytují výhodu vícenásobné rychlosti v úlohách hlubokého učení ve srovnání s Pascalem.
Pro tradiční výpočetní úlohy HPC a nové oblasti s využitím umělé inteligence, Nvidia vydala nový počítačový akcelerátor Tesla V100, založený na nové grafice (čistě nominálně, protože je určen pro zdaleka jen a ne tolik grafické práce), čip GV100. Zajímavé je, že nový čip je elektricky a fyzicky kompatibilní se starým - to bylo provedeno pro urychlení výroby a implementace nového produktu, protože můžete použít stejné základní desky, energetické systémy atd.

Fotografie nahoře ukazuje počítačový akcelerátor Tesla V100 založený na čipu GV100, který se narodil jako první v architektuře Volta a byl vyroben ve formovacím faktoru SXM2, přesně stejný jako již známý urychlovač Tesla P100 založený na Pascal GP100. V době svého oznámení je nejvýkonnějším paralelním procesorem na světě a vyznačuje se vysokým výpočtovým výkonem jak pro typické aplikace HPC, tak pro úlohy hlubokého učení, které vyžadují specifické zpracování velmi velkých datových souborů.
První GPU architektury Volta navíc využívá 16 GB vysokorychlostní paměti HBM2 vyvinuté ve spolupráci se společností Samsung, která má šířku pásma paměti 900 GB / s - o 50% vyšší než předchozí generace. A pro komunikaci mezi grafickými procesory a mezi grafickými a centrálními procesorovými jednotkami se používá vysokorychlostní rozhraní NVLink nové generace, které se ve srovnání s předchozím řešením - s rozlišením 300 GB / s, vyznačuje dvojnásobnou šířkou pásma.
Klíčové vlastnosti Tesla V100
- Nový design streamovacího multiprocesoru (SM) optimalizovaný také pro hluboké učení - v architektuře Volta byl multiprocesor SM seriózně přepracován a stal se o 50% energeticky účinnější než návrh Pascal multiprocesoru. Hlavní architektonické změny umožnily zvýšit výkon výpočtů FP32 a FP64 při stejné spotřebě energie, což je nejdůležitější úkol pro všechny výrobce čipů. Nový Tensor Cores, navržený speciálně pro školení a inferencování neuronových sítí v hlubokých problémech s učením, je schopen poskytnout až 12x vyšší rychlost (pro školení neuronových sítí a výpočty smíšené přesnosti). S nezávislými paralelními datovými toky pro výpočet celých čísel a pohyblivou řádovou čárkou je multiprocesor Volta také mnohem efektivnější ve smíšeném pracovním zatížení pomocí výpočetních a jiných operací. Nová funkce správy nezávislých vláken Volta umožňuje jemnou synchronizaci a interoperabilitu mezi paralelními vlákny. Nový kombinovaný subsystém ukládání dat do mezipaměti první úrovně (mezipaměť L1) a sdílené paměti (sdílená paměť) výrazně zvyšuje výkon některých úkolů a současně zjednodušuje jejich programování.
- Podporuje technologii vysokorychlostního propojení druhé generace NVLink umožňuje větší šířku pásma, více datových linek a lepší škálovatelnost pro systémy s více GPU a CPU. Nový procesor GV100 podporuje až šest kanálů NVLink 25 GB / s pro celkovou šířku pásma 300 GB / s. Druhá verze NVLink také podporuje nové funkce serverů založených na procesorech IBM Power 9, včetně koherence mezipaměti. Nová verze superpočítače DGX-1 Nvidia založeného na Tesla V100 používá NVLink k zajištění lepší škálovatelnosti a ultrarychlého školení neuronových sítí pro hluboké učení.
- Vysoce výkonná a efektivní paměť HBM2 Úložná kapacita 16 GB poskytuje maximální šířku pásma paměti až 900 GB / s. Kombinace rychlé paměti Samsung druhé generace a vylepšeného řadiče paměti v GV100 vedla k 1,5násobnému zvýšení šířky pásma paměti oproti předchozímu čipu Pascal GP100, zatímco nový GPU dosahuje více než 95% účinnosti šířky pásma v reálném pracovním zatížení.
- Funkce Multi-Process Service (MPS) umožňuje sdílení stejného GPU více procesy. Hardware architektury Volta urychluje kritické komponenty serveru CUDA MPS, aby se zlepšil výkon, izolace a nejlepší kvalita služba (QoS) pro více výpočetních aplikací pomocí jediné GPU. Volta také ztrojnásobil maximální počet klientů MPS - ze 16 pro Pascal na 48 pro Voltu.
- Vylepšený překlad sdílené paměti a adresy - v GV100 sdílená paměť používá nové ukazatele pro přenos paměťových stránek do procesoru, který k těmto stránkám přistupuje častěji. To zvyšuje účinnost přístupu k rozsahům paměti sdíleným mezi různými procesory. Za předpokladu, že jsou použity platformy IBM Power, umožňují nové služby pro překlad adres (ATS) GPU přímý přístup na stránky CPU.
- Spolupracující týmy a nová společná spuštění API - Cooperative Groups je nový programovací model zavedený v CUDA 9 pro organizování skupin souvisejících vláken. Spolupracující týmy umožňují vývojářům definovat granularitu, se kterou vlákna komunikují, což pomáhá organizovat efektivnější paralelní výpočet... Funkce Core Collaboration je podporována na všech GPU společnosti od Keplera, ale Pascal přidal podporu pro nová kooperativní spouštěcí API, která podporují synchronizaci mezi vláknovými bloky CUDA, a Volta přidal podporu pro nové synchronizační vzory.
- Režimy maximálního výkonu a maximální energetické účinnosti umožňují efektivnější využití GPU v různých případech. V režimu maximálního výkonu bude urychlovač Tesla V100 pracovat bez omezení frekvence se spotřebou energie až do úrovně TDP 300 W - tento režim je potřebný pro aplikace vyžadující nejvyšší výpočetní rychlost a maximální šířku pásma. Režim maximální účinnosti vám umožňuje vyladit spotřebu energie vašich urychlovačů Tesla V100, abyste získali nejlepší možný výkon na watt spotřeby energie. Přitom můžete nastavit horní lištu spotřeby pro všechny GPU v serverovém stojanu, čímž se sníží spotřeba energie při zachování dostatečného výkonu.
- Optimalizovaný software - nové verze struktur hlubokého učení, jako jsou Caffe2, MXNet, CNTK, TensorFlow a další, mohou využívat všechny možnosti Volty, aby výrazně zvýšily výkon školení a zkrátily dobu školení neuronových sítí. Knihovny cuDNN, cuBLAS a TensorRT optimalizované pro Voltu jsou schopny využít nové možnosti architektury Volta ke zlepšení výkonu úkolů hlubokého učení a známých vysoce výkonných počítačových aplikací (HPC). Nová verze CUDA Toolkit 9.0 již obsahuje nová a optimalizovaná API s podporou funkcí Volta.
Hardwarová architektura GV100
Inženýři Nvidia provedli mnoho změn na GV100 v porovnání s předchozími generacemi čipů, aby zlepšili výkon a efektivitu. To se týká jak typických aplikací HPC, tak úkolů využívajících hluboké učení, které může Volta doslova několikrát urychlit. Pojďme se na všechno podívat v pořádku.
Stejně jako podobný procesor GP100 z předchozí generace Pascalu se nový GV100 skládá z několika grafických procesorových klastrů (GPC), které zahrnují klastry pro zpracování textur (TPC), a také z řadičů paměti. Klastry TPC se zase skládají z několika streamovacích multiprocesorů (Streaming Multiprocessor (SM)), o nichž se budeme podrobněji zabývat později.
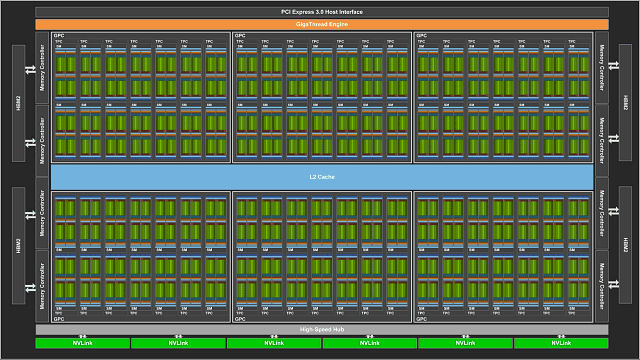
Obrázek ukazuje plnohodnotný čip GV100 s 84 multiprocesory, zatímco urychlovač Tesla V100 používá svou verzi s 80 aktivními SM multiprocesory. Plná verze výpočetní procesor Volta obsahuje šest GPC klastrů a 42 TPC klastrů, z nichž každý obsahuje dva SM multiprocesory. To znamená, že v čipu je 84 SM multiprocesorů, z nichž každý obsahuje 64 procesorových jader FP32, 64 jader INT32, 32 jader FP64 a 8 nových tenzorových jader se specializací na urychlení neuronových sítí. Každý multiprocesor také obsahuje čtyři texturové jednotky TMU.
V souladu s tím 84 plně funkčních procesorů nabízí plný čip GV100 výkon 5376 jader FP32 a INT32, 2688 jader FP64, 672 tenzorových jader a 336 texturovacích jednotek. Pro přístup k místní videopaměti má GPU osm 512bitových paměťových řadičů HBM2, které společně poskytují 4096bitovou paměťovou sběrnici. Každý rychlý zásobník paměti HBM2 je řízen vlastním párem paměťových řadičů a každý z paměťových ovladačů je připojen k mezipaměti L8 768KB, což dává GV100 celkem 6 MB mezipaměti L2.
Pojďme porovnat výpočetní akcelerátory společnosti Nvidia za posledních pět let podle jejich specifikací a špičkového výkonu (všechny výpočty jsou založeny na turbo frekvencích GPU):
| Model akcelerátoru | Tesla K40 | Tesla M40 | Tesla P100 | Tesla V100 |
| Model GPU | GK180 | GM200 | GP100 | GV100 |
| Architektura | Kepler | Maxwell | Pascal | Volta |
| Technický proces | 28 nm | 28 nm | 16 nm FinFET + | 12 nm FFN |
| Počet tranzistorů, miliarda | 7,1 | 8,0 | 15,3 | 21,1 |
| Velikost jádra, mm² | 551 | 601 | 610 | 815 |
| Množství SM | 15 | 24 | 56 | 80 |
| Množství TPC | 15 | 24 | 28 | 40 |
| Jádra FP32 na SM | 192 | 128 | 64 | 64 |
| Celkem jader FP32 | 2880 | 3072 | 3584 | 5120 |
| Jádra FP64 na SM | 64 | 4 | 32 | 32 |
| Celkový počet jader FP64 | 960 | 96 | 1792 | 2560 |
| Tenzorová jádra všeho | - | - | - | 640 |
| Turbo frekvence GPU, MHz | 810/875 | 1114 | 1480 | 1455 |
| Špičkový průtok FP32, teraflopy | 5,0 | 6,8 | 10,6 | 15,0 |
| Vrcholová oblast FP64, teraflopy | 1,7 | 2,1 | 5,3 | 7,5 |
| Vrcholový tenzor, teraflopy | - | - | - | 120 |
| Počet TMU | 240 | 192 | 224 | 320 |
| Paměťová sběrnice, bit | 384 | 384 | 4096 | 4096 |
| Typ paměti | GDDR5 | GDDR5 | HBM2 | HBM2 |
| Kapacita paměti, GB | Až 12 GB | Až 24 GB | 16 GB | 16 GB |
| Velikost mezipaměti L2, KB | 1536 | 3072 | 4096 | 6144 |
| Množství sdílené paměti na SM, KB | 16/32/48 | 96 | 64 | Až 96 KB |
| Velikost souboru registru, KB | 3840 | 6144 | 14336 | 20480 |
| TDP, W | 235 | 250 | 300 | 300 |
Lze jasně vidět jasný pokrok, k němuž došlo za několik let, i když vývoj nových technických procesů v TSMC není příliš rychlý. V posledních letech, i když nebereme v úvahu nové schopnosti tenzorových jader pro výpočty matic používané v úlohách hlubokého učení, se výpočty FP32 ztrojnásobily, pro FP64 je rozdíl více než čtyřnásobný a nový typ vysokorychlostní paměti umožnil výrazně zvýšit šířku pásma paměti.
To vše přirozeně vedlo ke stálé komplikaci čipů - GV100 (Volta) se stal třikrát složitější než GK180 (Kepler), ale díky zlepšování technologických procesů se velikost GPU rozrostla pouze jeden a půlkrát. Výpočetní procesor GV100 má fyzickou velikost zápustky 815 mm². Jedná se o působivý čip, zejména pro dosud dokonale vyladěnou novou 12nm technologii zpracování FFN - s největší pravděpodobností je jeho velikost blízko limitu pro továrnu TSMC. Chcete-li získat dobrou představu o tom, kolik to je, lze porovnat velikost čipu se senzory v digitálních fotoaparátech s plným rámečkem, které jsou jen o něco větší na 864 mm², ale byly vyrobeny pomocí mnohem méně složité litografie.
Když už mluvíme o 12nm FFN procesu TSMC. Toto je skutečně nejpokročilejší technologická technologie tchajwanské společnosti, která je dosud vhodná pro výrobu velkých a složitých čipů, jako je GV100. Jediné, co potřebujete vědět, je ve skutečnosti zmenšená verze známé technologické technologie FinFET 16 nm, čtvrtá verze této technologie se zlepšenými charakteristikami, která se neliší tolik jako čísla 12 a 16. TSMC se prostě rozhodla pojmenovat novým způsobem - aby usnadnit jim konkurenci společností Samsung a GlobalFoundries, které nabízejí procesní technologii 14 nm. Všechny tyto údaje dlouho neřekly nic zvláštního o skutečných kvalitách technického procesu, jsou velmi přibližné a mohou „chodit“ tam a zpět v závislosti na přání výrobců.
S tak obrovskou křišťálovou oblastí není překvapivé, že dokonce i použití nejpokrokovější 12-nanometrové technologie FFN umožnilo její výrobu pouze na okraji současných možností fotolitografie. Ukázalo se, že čip je ve všem velmi velký a nákladný, a tým Nvidia, zastoupený Johnem Albenem, senior viceprezidentem GPU designu, vyjádřil vděčnost prezidentovi společnosti Jensen Huang za to, že jim dal příležitost pracovat na tak komplexním a slibném projektu. Aby porozuměl složitosti problému jako celku, Jensen citoval následující data: v procesu vývoje architektury Volty a prvního výpočetního procesoru na jejím základě utratila společnost tři miliardy dolarů.
Volta Streaming Multiprocessor
Multiprocesory SM streamování jsou nám známy již několik generací výpočetních a grafických procesorů Nvidia. Architektura Volty prošla dalšími významnými změnami a úpravami, aby se zvýšil jejich výkon a efektivita. Nový model SM má nižší latenci pro provádění mezipaměti a provádění instrukcí než předchozí návrhy SM a také zahrnuje zcela nové možnosti pro zrychlení aplikací AI.
Klíčové vlastnosti multiprocesorů Volta:
- Nová tenzorová jádra se smíšenou přesností (FP16 / FP32) pro maticové výpočty používané v úlohách hlubokého učení;
- Vylepšená mezipaměť L1 s lepším výkonem a nižšími latencemi přístupu;
- Optimalizovaná sada instrukcí pro zjednodušení dekódování a snížení zpoždění provádění instrukcí;
- Speciální optimalizace pro dosažení vysokých rychlostí hodin a lepší energetické účinnosti.
Podobně jako u předchozího procesoru GP100 Pascal, nové procesory GV100 zahrnují 64 jader FP32 a 32 jader FP64 na SM. Pro zlepšení využití výpočetního bloku a celkového výkonu však nové SM používají nové schéma sdílení prostředků.
Pokud je multiprocesor GP100 rozdělen do dvou procesorových jednotek, z nichž každá má 32 jader FP32, 16 jader FP64, vyrovnávací paměť instrukcí, jeden plánovač osnovy, dva dispečerské bloky a registrový soubor 128 KB, pak je multiprocesor GV100 rozdělen do čtyř procesorové jednotky, z nichž každá má 16 jader FP32, 8 jader FP64, 16 jader INT32, dvě nová tenzorová jádra, novou instrukční mezipaměť nulové úrovně (L0), jeden plánovač osnovy, jeden dispečerský blok a soubor registru 64 KB ... Zde je poměrně podrobný diagram SM:
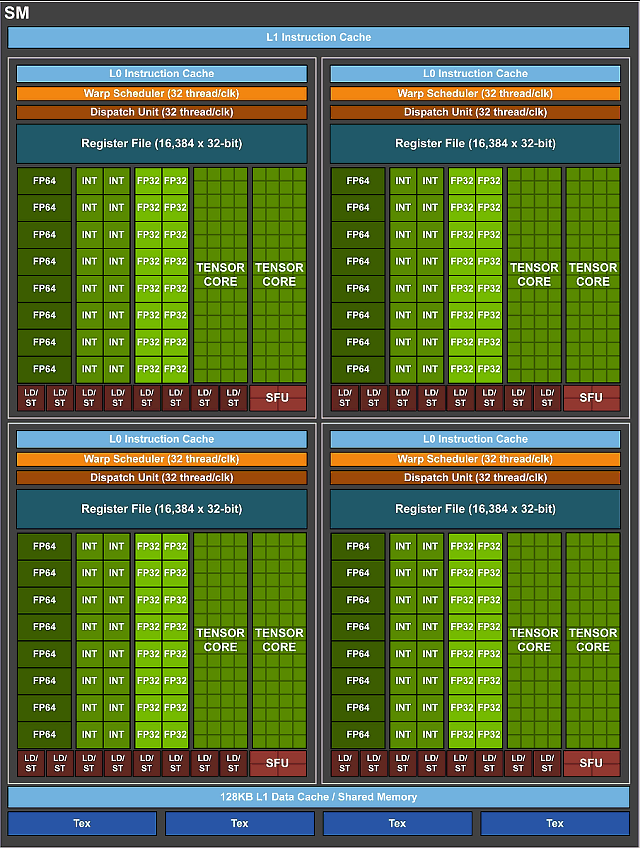
Každý oddíl má nyní novou vyrovnávací paměť úrovně 0, která je účinnější než vyrovnávací paměti instrukcí používané v předchozích GPU Nvidia. Přestože multiprocesory v GV100 mají stejný počet registrů jako SM v GP100, výpočetní procesor jako celek má mnohem více SM a více registrů. Tyto změny vedly k tomu, že GV100 podporoval více souběžně provádějící vlákna, osnovy a bloky vláken ve srovnání s předchozími generacemi GPU.
Celková sdílená paměť pro celý výpočetní procesor GV100 je zvýšena zvýšením počtu multiprocesorů a možností konfigurovat sdílenou paměť až na 96 kB na SM (z 128 kB vyhrazených pro datovou mezipaměť L1 a sdílenou paměť společně) oproti 64 kB v předchozí generaci GP100.
Jednou z nejdůležitějších změn v nových multiprocesorech Volta je to, že obsahují samostatné jádra FP32 a INT32, což umožňuje provádění instrukcí FP32 a INT32 současně plnou rychlostí, což zlepšuje využití bloků a celkový výkon GPU. Dekodéry a plánovače provádějí jednu instrukci a jednu warp za cyklus hodin a celkově je dvakrát více příkazů a warpů provedeno na multiprocesor za cyklus hodin, ve srovnání s Pascalem.
Předchozí rodiny GPU, včetně Pascalu, nemohou provádět instrukce FP32 a INT32 současně, ale pouze postupně, což negativně ovlivňuje výkon některých úkolů. Nová architektura s více procesory umožňuje provádění pokynů FP32 plnou rychlostí a použití zbývající poloviny emisních slotů k provádění dalších typů instrukcí: INT32, FP64, načtení / uložení, větev, speciální funkce SFU atd., Což zefektivňuje výpočetní GPU.
Tempo provádění instrukcí se také zvýšilo u fúzovaných matematických operací s vícenásobným přidáním (FMA), které vyžadují na Voltě pouze čtyři hodinové cykly, v porovnání se šesti cykly na Pascalu. A protože existuje méně fází pro provedení, pak odpovídající bloky provedení, s největší pravděpodobností, trvat méně plochy na čipu. Pravda, delší potrubí jsou obvykle schopna provozu na vyšší frekvenci, ale stále to závisí na mnoha dalších faktorech: fyzický design, technický proces, spotřeba energie atd. Soudě podle prvních dat je vše v pořádku s frekvencí procesoru GV100.
Tenzorová jádra
Předchozí generátor urychlovače Tesla P100 již poskytoval výrazně vyšší výkon v trénování neuronových sítí ve srovnání s řešeními založenými na GPU ještě dřívějších generací: Maxwell a Kepler, ale potřeba školení a inferencování neuronových sítí rostoucí velikosti a složitosti neustále roste a možnosti Pascal už pro vědce nestačí. Používají neuronové sítě tisíců vrstev a miliónů neuronů, což vyžaduje ještě větší výpočetní rychlost.
A obvyklé 1,5násobné zvýšení rychlosti získané z každého nového modelu GPU je zde zjevně nedostatečné. Právě s cílem uspokojit potřeby trhu pro růst výkonu se společnost Nvidia rozhodla implementovat do svého výpočetního procesoru Volta nový typ jader - Tensor Cores. Tato jádra jsou nejvíce důležitá funkce nová Volta architektura, která pomůže dosáhnout mnohonásobného zvýšení výkonu při tréninku a odvozování problémů velkých neuronových sítí.
Maticové multiplikační operace (BLAS GEMM) jsou základem učení a inference (proces, který je inverzní k učení - závěry založené na již „inteligentní“ neuronové síti) neuronových sítí, používají se k násobení velkých matic vstupních dat a hmotností ve spojených vrstvách sítě. Tenzorová jádra se specializují na provádění těchto multiplikací a mohou výrazně zvýšit výkon takových výpočtů s pohyblivou řádovou čárkou při zachování relativně nízké složitosti tranzistoru a stopy těchto jader na GPU. Současně se výrazně zvyšuje energetická účinnost.
![]()
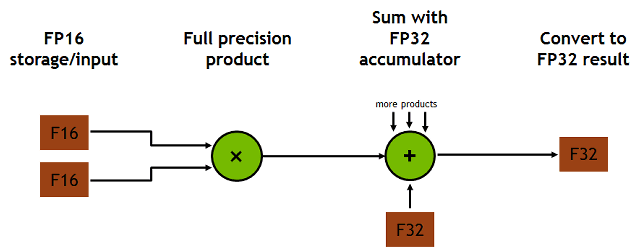
Architektura Volta GPU podporuje nové pokyny a datové formáty vhodné pro práci s maticovými poli 4x4. Každé tenzorové jádro zpracovává maticové matice 4x4x4 provedením operace D \u003d AxB + C, kde A, B, C a D jsou matice 4x4. Výpočetní jádra čtou dvě hodnoty s přesností FP16, sbalené do jednoho registru (matice A a B), vynásobí se přesností FP32, výsledek se přičte k hodnotě FP32 nebo FP16 a zapíše se s 32bitovou nebo 16bitovou přesností. U úloh hlubokého učení je tato přesnost dostačující a je možné, že schopnosti tenzorových jader budou užitečná i v jiných úkolech.
Každé tenzorové jádro provádí 64 operací s plovoucí desetinnou čárkou s kombinovanou přesností s vícenásobným přidáním (FMA) v jednom hodinovém cyklu. Výpočtová přesnost v této operaci je smíšená, několikanásobné násobení dvou matic FP16 se provádí s přesností FP32, kumulace se také provádí s přesností FP32 a výsledek je výstup ve formátu FP32.
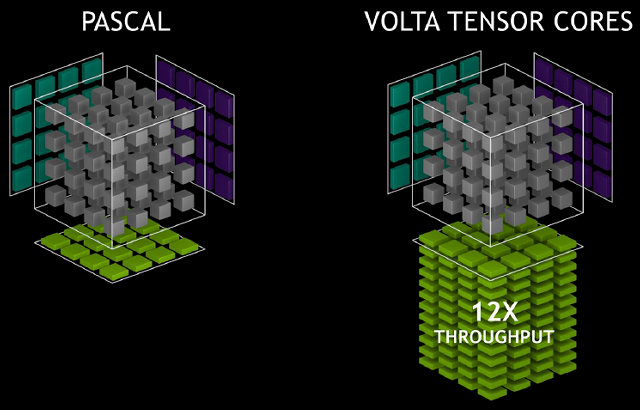
Osm tenzorových jader v každém SM multiprocesoru provádí celkem 1 024 operací s pohyblivou řádovou čárkou za hodinový cyklus, osmkrát rychlejší než pascalský multiprocesor s použitím standardních operací FP32. Celkově se tím při porovnání výpočetního procesoru GP100 promítá do 12x zlepšení hlubokého učení.
Během provádění daného programu používá výkonná osnova současně několik tenzorových jader. Několik vláken v osnově poskytuje velkou operaci na matici 16x16x16, která je zpracovávána tenzorovými jádry. Schopnost provádět takové operace je poskytována v CUDA C ++ API, toto rozhraní poskytuje specializované načítání matic, násobení a akumulaci matric, jakož i operace ukládání matic pro efektivnější využití tenzorových jader v programech CUDA.
Kromě nových schopností CUDA mohou být knihovny přímo z CUDA 9 použity také pro přímé programování tenzorových jader: cuBLAS a cuDNN zahrnují nové funkce pro použití tenzorových jader v aplikacích a rámcích pro hluboké učení. Nvidia spolupracuje s vývojáři populárních hlubokých studijních rámců, jako jsou Caffe2 a MXNet, aby zajistila, že každý může použít tenzorová jádra Volty ve vědeckém výzkumu pomocí neuronových sítí.
V čipu GV100 je 640 tenzorových jader - 8 pro každý multiprocesor. Všichni společně jsou schopni poskytnout až 120 specializovaných tenzorových teraflopů pro výcvik a odvozování, což je 12násobek maximální hodnoty GP100 při použití přesnosti FP32 a 6krát více při použití operací FP16. V praxi se ukazuje, i když ne 12, ale poněkud méně, ale také velmi slušně.
Následující obrázek ukazuje, jak Tesla V100 Tensor Cores zlepšuje výkon cuBLAS (GPU Accelerated Basic Linear Algebra Operations Library) více než 9x ve srovnání s urychlovačem Tesla P100 založeným na čipu architektury Pascal.
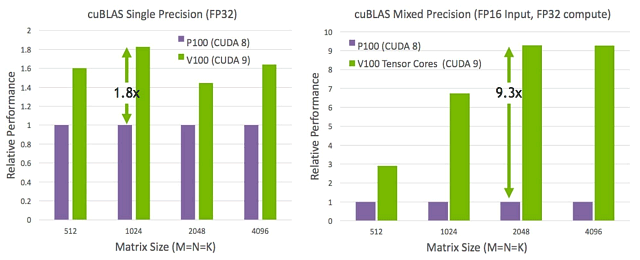
Předprodejní vzorek Tesla V100, na kterém běží CUDA 9, byl díky specializovaným tenzorovým jádrům schopen provádět velké násobení matic (GEMM) 9,3krát rychlejší než Tesla P100 (se smíšenou přesností). Samozřejmě, pokud má vývojář požadavek na použití přesnosti FP32 pro vstupní data, rozdíl se ukáže být znatelně menší - 1,8krát, ale i v tomto případě je nárůst docela patrný.
Přesnost FP16 však obvykle postačuje pro nácvik neuronových sítí, v tomto případě lze plně využít schopnosti tenzorových jader pro násobení matic a rozdíl v rychlosti je téměř řádově velký - mnoho vědců používajících hluboké učení se bude takový skok opravdu líbit. Například, pokud trénink neuronové sítě trvá pouze den nebo dokonce půl dne namísto týdne, bude takový rozdíl velmi snadno cítit a vyhodnotit.
Teoreticky lze tenzorová jádra použít nejen v hlubokých problémech učení, ale také v jiných oblastech, kde se používají podobné operace s maticemi. Existují-li nějaké a může to být například nějaké následné zpracování, pak mohou být použity v budoucnosti a v grafických úlohách. V grafickém rozhraní API bude nutné tyto funkce odhalit, i když i když nebudou zahrnuty do jejich budoucích verzí, pak má společnost Nvidia vždy příležitost nabídnout vývojářům tyto funkce stejným způsobem, jaké se používají u jiných specifických technologií společnosti.
Jde však pouze o teoretickou teorii, protože dosud není známo, zda budou tenzorová jádra zachována ve „herních“ GPU. Na jedné straně je zrychlení téhož závěru užitečné na koncových zařízeních a nejen na serverech, které trénují neuronové sítě. Na druhé straně je možné, že tato jádra budou stát v herních čipech příliš mnoho a použití těchto funkcí bude příliš vzácné. V každém případě je rozhodnutí na Nvidii - pokud najdou dostatečnou motivaci k tomu, aby si udržovali tenzorová jádra ve svých herních rozhodnutích, budou. Ale musíte být připraveni na skutečnost, že nemusí být ve hře Volta.
Vylepšené ukládání do mezipaměti a sdílená paměť
GV100 neproběhl bez změn v mezipaměti subsystému. Architektura Volta používá novou, rychlou kombo paměť na čipu, která kombinuje datovou mezipaměť L1 a sdílenou paměť. Tato implementace zlepšuje výkon, zjednodušuje složitost programování u některých úkolů a snižuje potřebu manuálních optimalizací pro dosažení výkonu na špičce.
Kombinace datové mezipaměti L1 a sdílené paměti do jednoho bloku umožňuje nejlepší výkon pro oba typy přístupu k paměti. Celková kapacita těchto typů paměti v GV100 je 128 kB na multiprocesor, který je několikrát větší než datová mezipaměť GP100, a celou tuto paměť lze také použít jako mezipaměť u programů, které nepoužívají sdílenou paměť. Texturové jednotky v SM také používají stejnou paměť cache. Nejjednodušší příklad rozdělení je stejně, když je sdílená paměť nakonfigurována na 64 kB a zbývajících 64 kB může být použito jako mezipaměť L1 pro operace textury a načítání / ukládání.
Integrace mezipaměti L1 sdílené paměti zajišťuje, že tato mezipaměť na GV100 má mnohem nižší latenci a vyšší propustnost ve srovnání s mezipamětí L1 v předchozích GPU společnosti. Volta Layer 1 cache funguje jako streamovací kanál s velkou šířkou pásma a současně poskytuje nízko-latenční přístup k často přístupným datům kombinací těchto dvou.
Hlavním důvodem tohoto sloučení datové mezipaměti L1 se sdílenou pamětí v GV100 je dosažení vyššího výkonu sdílené paměti pro operace mezipaměti L1. Sdílená paměť poskytuje vysokou šířku pásma a nízkou latenci, ale programátoři musí tuto paměť sami spravovat. Nová výpočetní architektura společnosti Nvidia zmenšuje rozdíl v rychlosti mezi aplikacemi, které samy spravují sdílenou paměť, a těmi, které upřednostňují přístup k datům ve video paměti a spoléhají na ukládání do mezipaměti L1.
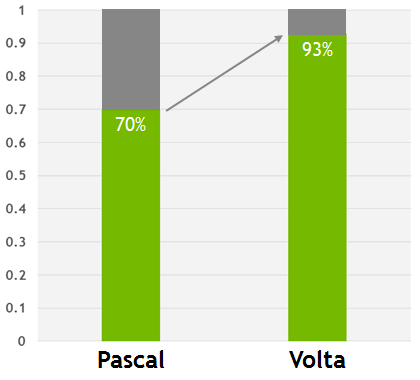
Volta L1 cache eliminuje rozdíl mezi aplikacemi, které jsou ručně konfigurovány pro ukládání dat do sdílené paměti, a těmi, které přistupují k datům uloženým přímo v místní paměti. Ve výše uvedeném diagramu se 1,0 rovná výkonu aplikace nakonfigurované pro použití výhradně sdílené paměti a dva sloupce pro Pascal a Volta představují výkon ekvivalentních aplikací, které nepoužívají sdílenou paměť.
V souladu s tím nová architektura umožňuje přistupovat k ideální situaci, když není tak důležité, která metoda přístupu k paměti je použita. I když sdílená paměť stále zůstává nejlepší volba pro maximální výkon (7% není vůbec zbytečné), ale nová kombo cache ve Voltě umožňuje programátorům snadno získat dostatečně vysoký výkon bez nutnosti ruční optimalizace.
Nezávislá regulace průtoku
Jednou z největších a nejsložitějších změn ve Voltě jsou nové plánovače vláken a dispečerské jednotky, a tím i algoritmy řízení vláken a osnov, které se staly efektivnějšími. Architektura Volta jako celek byla navržena pro další zjednodušení programování GPU v předchozích generacích, což by mělo zvýšit produktivitu programátorů, což je zvláště důležité pro komplexní aplikace.
Procesor GV100 Compute Processor je prvním GPU podporujícím nezávislé plánování vláken (plánování), které poskytuje přesnější načasování a lepší interakci mezi paralelními vlákny. Jedním z hlavních cílů při vývoji nové architektury bylo zkrátit dobu potřebnou k vývoji efektivní práce programy na GPU a také poskytnout větší flexibilitu v komunikaci mezi vlákny.
Modely provádění SIMT (s jednoduchou instrukcí, více vlákny) v předchozích GPU od společnosti a Volty se mírně liší. Voltův model SIMT umožňuje stejnou souběžnost mezi všemi vlákny, bez ohledu na warp, a udržuje stav provádění pro každé vlákno, včetně programového čítače a zásobníku volání.
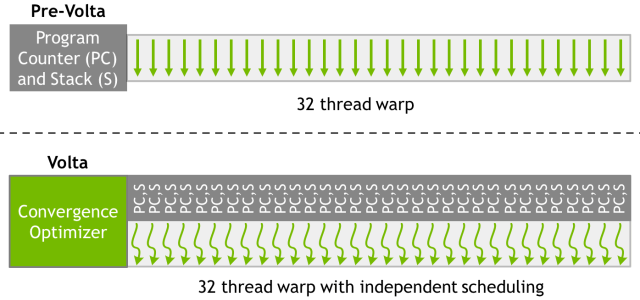
Na obrázku je architektura plánování nezávislých vláken Volta ve srovnání s Pascalem a dřívějšími architekturami. Volta ukládá plánovací prostředky pro každé vlákno, jako je programový čítač (PC) a zásobník volání (S), zatímco dřívější architektury tyto zdroje ukládaly pouze pro každou warp. Nezávislé řízení podprocesů Volty umožňuje výpočetnímu procesoru provádět libovolné vlákno, aby bylo možné lépe využívat výpočetní prostředky, nebo umožnit jednomu vláknu čekat na data z jiného.
Pro zvýšení účinnosti paralelního provádění má Volta optimalizátor plánu, který seskupuje aktivní vlákna ze stejné osnovy do bloků SIMT. To udržuje tempo provádění SIMT tak rychle jako v předchozích procesorech Nvidia, ale s větší flexibilitou: ve Voltě se vlákna mohou odchylovat a konvergovat ve warpu a GPU bude sdružovat vlákna provádějící stejný kód a paralelně je spouštět.
Provedení pokračuje podle modelu SIMT, pro jakýkoli cyklus hodin jádra CUDA provádějí stejnou instrukci pro všechna aktivní vlákna v osnově, udržujíc tak účinnost provádění na úrovni předchozích architektur. Schopnost Volty manipulovat s toky uvnitř osnovy umožňuje složitější algoritmy a datové struktury. Přestože plánovač podporuje nezávislé provádění podprocesů, optimalizuje kód mimo synchronizaci, aby zajistil, že model SIMT bude prováděn co nejefektivněji.
CUDA 9 a nové výpočetní schopnosti
Vyhlášení nového výpočetního procesoru také způsobilo vznik nové verze softwarové platformy pro GPU computing - CUDA 9, která získala aktualizované výpočetní schopnosti. Devátá verze balíčku plně podporuje architekturu Volta a počítačový akcelerátor Tesla V100 a obsahuje také počáteční podporu specializovaných tenzorových jader, která poskytují velké zisky rychlosti pro maticové operace se smíšenými výpočty přesnosti, které se široce používají v problémech hlubokého učení.
Počítačový procesor GV100 podporuje další úroveň výpočetního výkonu - výpočetní schopnost 7.0. V tabulce jsou uvedeny rozdíly ve výpočetní kapacitě a meziprocesorových limitech pro různé architektury a řešení od společnosti Nvidia: Kepler, Maxwell, Pascal a Volta.
| GPU | GK180 | GM200 | GP100 | GV100 |
| Architektura | Kepler | Maxwell | Pascal | Volta |
| Vypočítat schopnost | 3.5 | 5.2 | 6.0 | 7.0 |
| Proudy do osnovy | 32 | 32 | 32 | 32 |
| Počet osnov na SM | 64 | 64 | 64 | 64 |
| Počet toků na SM | 2048 | 2048 | 2048 | 2048 |
| Počet bloků vláken na SM | 16 | 32 | 32 | 32 |
| Počet 32bitových registrů na SM | 65536 | 65536 | 65536 | 65536 |
| Počet registrů na blok | 65536 | 32768 | 65536 | 65536 |
| Počet registrů v proudu | 255 | 255 | 255 | 255 |
| Velikost bloku toků | 1024 | 1024 | 1024 | 1024 |
| Jádra FP32 na SM | 192 | 128 | 64 | 64 |
| Počet registrů na jádro FP32 | 341 | 512 | 1024 | 1024 |
| Sdílená paměť na SM, KB | 16/32/48 | 96 | 64 | Až 96 |
Společnost Nvidia se díky své inteligentní strategii v průběhu let stala jednou z nejdůležitějších sil na trhu s vysoce výkonnými výpočetními prostředky a její řešení již používá mnoho jejích partnerů. Nové technologie společnosti Nvidia pomáhají rozvíjet vizuální a další výpočetní průmysl a výzkum umělé inteligence. Další vývoj může dále oddělit výpočetní a zábavní aplikace, ale je to jejich kombinace, která umožnila a nadále umožňuje společnosti získat maximum z různých trhů.
Najednou, jen hráči zaplatili za pokrok ve vývoji GPU, nyní se k nim přidali mnohem vážnější kluci, kteří se brzy stanou neméně, ne-li důležitější, silou, kterou bude třeba stále více poslouchat. Stávající výpočetní řešení založená na čipu GP100 se již liší od herních karet založených na podobných, ale daleko od identických GP102, a v budoucnu se rozdíl může zvýšit - například není skutečností, že herní řešení založená na Voltě potřebují tenzorová jádra. Prozatím.
Nemá však smysl úplně oddělit výpočetní a grafická řešení - jsou stále velmi blízká z čistě technologického hlediska, protože plní do značné míry podobné úkoly az finančního hlediska je správnější vzít v úvahu dvě oblasti, které tam i tam přinášejí zisk. Proto prozatím můžeme od „grafických“ řešení očekávat funkčnost a výkon architektury Volta, která je podobná výpočetní vlajkové lodi (samozřejmě s ohledem na různý počet funkčních bloků a případnou absenci tenzorových jader), alespoň pro nejrozšířenější výpočty FP32. Obecně - podívejme se, výhoda čekání je stále méně.