Sarcinile sistemelor de coadă (QS). Cele mai simple sisteme de coadă, exemple de utilizare în rezolvarea problemelor economice
Obiect matematic (abstract), ale cărui elemente sunt (fig. 2.1):
- flux de intrare (de intrare) de aplicații (cerințe) pentru deservire;
- dispozitive de service (canale);
- coada de aplicații care așteaptă serviciul;
- fluxul de ieșire (ieșire) al aplicațiilor servite;
- fluxul de cerere de întrerupere după serviciu;
- fluxul de aplicații nesolicitate.
Cerere (cerere, cerință, apel, client, mesaj, pachet) - un obiect care ajunge la QS și necesită service în dispozitiv. Se formează setul de aplicații consecutive, distribuite în timp flux de intrare de aplicații.
Fig. 2.1.
Instrument de service (dispozitiv, dispozitiv, canal, linie, pistol, mașină, router etc.) - element QS al cărui scop este să servească aplicații.
Serviciu - o întârziere a aplicației în dispozitivul de service pentru o perioadă de timp.
Durata serviciului - aplicații de întârziere (service) în dispozitiv.
Dispozitiv de stocare (buffer, buffer de intrare, buffer de ieșire) - un set de locuri pentru așteptarea aplicațiilor în fața dispozitivului de servire. Numărul locurilor de așteptare - capacitate de stocare.
O cerere primită în QS poate fi în două state:
- 1) de serviciu (în dispozitiv);
- 2) așteptări (în unitate), dacă toate dispozitivele sunt ocupate pentru deservirea altor aplicații.
Cereri care sunt în unitate și în așteptare formular de servicii coadă aplicații. Numărul de aplicații în serviciu în așteptare este: lungimea cozii.
Disciplina de tamponare (disciplina cozii) - regula înregistrării aplicațiilor primite în unitate (buffer).
Disciplina serviciului - regula selectării aplicațiilor din coada pentru deservirea dispozitivului.
Prioritate - dreptul de preempțiune (preluarea resurselor) pentru a fi introdus în unitate sau selectat din coadă pentru service în dispozitivul aplicațiilor dintr-o clasă în raport cu aplicațiile altor clase.
Există multe sisteme de coadă care diferă în organizarea structurală și funcțională. În același timp, dezvoltarea metodelor analitice pentru calcularea indicatorilor de performanță a QS în multe cazuri presupune prezența unui număr de limitări și ipoteze care restrâng setul de QS studiate. prin urmare nu există un model analitic universal pentru o structură complexă QS arbitrară.
Modelul analitic al QS este un set de ecuații sau formule care vă permit să determinați probabilitățile stărilor sistemului în timpul funcționării și indicatorilor de performanță a acestuia, prin parametrii cunoscuți ai fluxurilor primite și ai canalelor de servicii, disciplinele de tamponare și întreținere.
Modelarea analitică a QS este facilitată în mod semnificativ dacă procesele care apar în QS sunt Markov (fluxurile de aplicații sunt simple, timpul de service este distribuit exponențial). În acest caz, toate procesele din QS pot fi descrise prin ecuații diferențiale obișnuite, iar în cazul de limitare, pentru stări staționare, prin ecuații algebrice liniare și, după ce le-au rezolvat prin orice metode disponibile în pachetele software matematice, determinați indicatorii de performanță selectați.
În sistemele de IM, atunci când implementează QS, se fac următoarele limitări și ipoteze:
- cerere primită în sistem imediat intră în funcțiune dacă nu există solicitări în coadă și dispozitivul este gratuit;
- în dispozitiv pentru service în orice moment al timpului poate fi doar unu cerere;
- după finalizarea serviciului oricărei aplicații din dispozitiv, următoarea aplicație este selectată din coada de serviciu instantaneu, adică dispozitivul nu inactiv dacă există cel puțin o solicitare în coadă;
- primirea cererilor în QS și durata deservirii acestora nu depind de numărul de aplicații care există deja în sistem sau de alți factori;
- durata serviciului aplicațiilor nu depinde de intensitatea primirii cererilor în sistem.
Să ne lămurim mai detaliat pe unele elemente ale QS.
Flux de intrare (de intrare) de aplicații. Flux de evenimente se numește o secvență de evenimente omogene care se succed una după alta și au loc în unele, în general, aleatoriu clipe de timp. Dacă evenimentul este aspectul aplicațiilor, avem flux de aplicații. Pentru a descrie fluxul de aplicații în cazul general, este necesar să se stabilească intervalele de timp m \u003d t k - t k-1 între momentele adiacente t k _ k și t k primirea cererilor cu numere de serie la - 1 și la respectiv (la - 1, 2, ...; t 0 - 0 este momentul inițial al timpului).
Principala caracteristică a fluxului de aplicație este intensitate X - numărul mediu de cereri primite la intrarea QS pe unitatea de timp. Valoarea m \u003d 1 / X definește intervalul mediu de timp între două solicitări consecutive.
Stream apelat determinat dacă intervale de timp t la Între aplicațiile vecine, anumite valori prestabilite sunt acceptate. Dacă intervalele sunt aceleași (x până la \u003d t pentru toți k \u003d 1, 2, ...), atunci se numește fluxul regulat. Pentru o descriere completă a fluxului regulat al aplicațiilor, este suficient să setați intensitatea fluxului Xsau valoarea intervalului m \u003d 1 / X.
Fluxul în care intervale de timp x la între aplicațiile adiacente sunt numite variabile aleatoare aleatoriu. Pentru o descriere completă a fluxului aleatoriu al aplicațiilor în cazul general, este necesar să se stabilească legile de distribuție F fc (x fc) pentru fiecare dintre intervalele de timp x k, k \u003d 1,2, ...
Flux aleatoriu în care intervale toate timpurile x b x 2... între cererile consecutive adiacente sunt variabile aleatoare independente descrise de funcțiile de distribuție FjCij), F 2 (x 2), ... respectiv, se numește flux cu afterffect limitat.
Flux aleatoriu apelat recurent dacă la intervale de timp x b t 2 ... distribuite între aplicații prin aceeași lege F (t). Există multe fluxuri recurente. Fiecare lege de distribuție generează propriul flux recurent. Fluxurile recurente sunt de altfel numite fluxuri de palmier.
Dacă intensitatea X iar legea de distribuție F (t) a intervalelor dintre aplicațiile consecutive nu se schimbă cu timpul, atunci se numește fluxul de aplicații staționar În caz contrar, fluxul aplicației este inconstant.
Dacă în fiecare moment din timp t k la intrarea QS poate apărea o singură aplicație, apoi se apelează fluxul de aplicații comun. Dacă la un moment dat pot apărea mai mult de o comandă, atunci fluxul de ordine - extraordinar sau grup.
Fluxul de revendicări este denumit flux de revendicări. fără afterffect, dacă se primesc cereri indiferent de în afară, adică momentul primirii următoarei cereri nu depinde de când și de câte cereri au fost primite până în acest moment.
Fluxul obișnuit staționar fără efect aferent se numește cel mai simplu.
Intervalele de timp m între aplicațiile în fluxul cel mai simplu sunt distribuite exponențială (indicativ) legea: cu funcția de distribuție F (t) \u003d 1 - e ~ m; densitatea de distribuție / (f) \u003d Heh ~ "l, Unde X\u003e 0 - parametru de distribuție - fluxul de aplicații.
Cel mai simplu flux este adesea numit poisson. Numele provine de la faptul că pentru acest flux probabilitatea de apariție a P fc (At) este exact la aplicații pentru un anumit interval de timp At este determinat legea lui Poisson:

Trebuie menționat că fluxul Poisson, spre deosebire de cel mai simplu, poate fi:
- staționar dacă intensitatea X nu se schimbă cu timpul;
- nestaționară dacă debitul depinde de timp: X \u003d\u003e. (t).
În același timp, cel mai simplu flux, prin definiție, este întotdeauna staționar.
Studiile analitice ale modelelor de coadă sunt adesea realizate sub presupunerea unui flux simplu de aplicații, care se datorează unei mai multe caracteristici remarcabile inerente acestuia.
1. Sumare (asociere) a fluxurilor. Cel mai simplu flux în teoria QS este similar cu legea normală de distribuție în teoria probabilităților: trecerea la fluxul cel mai simplu este cauzată de trecerea la limită, care este suma fluxurilor cu caracteristici arbitrare cu o creștere infinită a numărului de termeni și o scădere a intensității acestora.
Cantitate N fluxuri ordinare staționare independente cu intensități X b X 2 ,..., X n formează fluxul cel mai simplu cu intensitate
X \u003d Y, ^ i cu condiția ca fluxurile adăugate să aibă mai mult sau
efect mai puțin egal la nivelul fluxului total. În practică, fluxul total este aproape de cel mai simplu pentru N\u003e 5. Deci la însumarea fluxurilor simple independente, fluxul total va fi cel mai simplu la orice valoare N.
- 2. Rarefarea probabilistică a fluxului. probabilistica (dar nu determinist) rarefierea curent simplu aplicații în care orice aplicație la întâmplare cu o oarecare probabilitate rexcluse din flux, indiferent dacă alte aplicații sunt excluse sau nu, conduce la formarea curent simplu cu intensitate X * = pX Unde X - intensitatea fluxului sursă. Fluxul de excludere a intensității X ** \u003d (1 - p) X - de asemenea cel mai simplucurgere.
- 3. Eficiență. Dacă canalele de service (dispozitive) sunt proiectate pentru fluxul cel mai simplu de aplicații cu intensitate X atunci serviciile altor tipuri de fluxuri (cu aceeași intensitate) vor fi furnizate fără o eficiență mai mică.
- 4. Simplitatea. Asumarea celui mai simplu flux de aplicații permite pentru multe modele matematice să obțină în mod explicit dependența indicatorilor QS de parametri. Cel mai mare număr de rezultate analitice a fost obținut pentru cel mai simplu flux de aplicații.
Analiza modelelor cu fluxuri de aplicații diferite de cele mai simple complică de obicei calcule matematice și nu permite întotdeauna obținerea unei soluții analitice într-o formă explicită. Numele „cel mai simplu” a fost primit tocmai datorită acestei caracteristici.
Aplicațiile pot avea drepturi diferite pentru a începe serviciul. În acest caz, ei spun că aplicațiile eterogen. Avantajele unor fluxuri de aplicații față de altele la începutul serviciului sunt prioritare.
O caracteristică importantă a fluxului de intrare este coeficientul de variație

unde t int - așteptarea matematică a lungimii intervalului; despre - abaterea standard a lungimii intervalului x int (valoare aleatorie).
Pentru fluxul cel mai simplu (a \u003d -, m \u003d -) avem v \u003d 1. Pentru majoritatea
fire reale 0
Canale (dispozitive) de serviciu. Principala caracteristică a canalului este durata serviciului.
Durata serviciului - timpul petrecut de aplicație în dispozitiv - în general, valoarea este aleatorie. În cazul unei încărcări QS neomogene, timpul de utilizare pentru aplicații din clase diferite poate diferi în funcție de legile distribuțiilor sau numai de valorile medii. În acest caz, se presupune, de regulă, că durata de deservire a aplicațiilor pentru fiecare clasă este independentă.
Adesea, practicienii iau în considerare durata aplicațiilor de serviciu distribuite pe mai multe lege exponențială ceea ce simplifică mult calculele analitice. Acest lucru se datorează faptului că procesele care au loc în sisteme cu o distribuție exponențială a intervalelor de timp sunt markov procese:
unde c - intensitatea serviciului aici p \u003d _--; t 0 bsl - mate-
așteptați timpul de serviciu.
Pe lângă distribuția exponențială, se găsesc și distribuția Erlang / c, hiperexponențială, triunghiulară și altele. Acest lucru nu trebuie să ne confunde, deoarece se arată că sensul criteriilor pentru eficiența QS depinde puțin de forma legii distribuției timpului de serviciu.
În studiul QS, esența serviciului și calitatea serviciilor nu iau în considerare.
Canale pot fi absolut de încredere acestea. Nu da greș. Mai degrabă, acest lucru poate fi acceptat în studiu. Canalele pot avea fiabilitate finală. În acest caz, modelul QS este mult mai complicat.
Eficiența QS depinde nu numai de parametrii fluxurilor de intrare și de canale de servicii, ci și de ordinea în care sunt difuzate cererile primite, adică. de la metodele de gestionare a fluxului de aplicații la intrarea lor în sistem și trimiterea acestora pentru service.
Modalitățile de gestionare a fluxurilor de aplicații sunt determinate de discipline:
- tamponare;
- serviciu.
Dispozitivele de tamponare și întreținere pot fi clasificate după următoarele criterii:
- prezența priorităților între aplicațiile diferitelor clase;
- o modalitate de a scoate cererile din coadă (pentru disciplinele de tamponare) și de a atribui cererile de servicii (pentru disciplinele de serviciu);
- regula pentru aglomerarea sau selectarea cererilor de servicii;
- capacitatea de a schimba prioritățile.
În fig. Este prezentată o variantă a clasificării disciplinelor de tamponare (coada) în conformitate cu caracteristicile enumerate. 2.2.
Depinzând de disponibilitate sau lipsa de prioritate între cererile din clase diferite, toate disciplinele de tamponare pot fi împărțite în două grupuri: prioritate și prioritate.
De metoda de aglomerare a aplicațiilor din unitate Se pot distinge următoarele clase de discipline tampon:
- fără aglomerarea aplicațiilor - aplicațiile care au intrat în sistem și au făcut unitatea complet plină se pierd;
- cu aglomerarea aplicației acestei clase, adică. aceeași clasă ca și cererea primită;
- cu extinderea aplicației din clasa cu prioritate cea mai mică;
- cu aglomerarea unei aplicații dintr-un grup de clase cu prioritate redusă.

Fig. 2.2.
Disciplinele de tamponare pot utiliza următoarele reguli pentru extragerea aplicațiilor de pe unitate:
- aglomerarea accidentală;
- extinderea ultimei aplicații, adică a intrat în sistem mai târziu decât toate;
- extinderea unei aplicații „lungi”, adică stocate în unitate mai mult decât toate aplicațiile primite anterior.
În fig. 2.3 Clasificarea disciplinelor aplicațiilor de serviciu este prezentată în conformitate cu aceleași caracteristici ca și pentru disciplinele de tamponare.
Uneori, capacitatea de acționare a modelelor este considerată nelimitată, deși într-un sistem real este limitată. O astfel de presupunere este justificată atunci când probabilitatea pierderii unei aplicații într-un sistem real datorită supraîncărcării capacității de stocare este mai mică de 10 _3. În acest caz, disciplina practic nu afectează performanța aplicațiilor de servicii.
Depinzând de disponibilitate sau lipsa de prioritate între aplicațiile din diferite clase, toate disciplinele de serviciu, precum și disciplinele de tamponare, pot fi împărțite în două grupuri: neprioritate și prioritate.
De metoda de atribuire a cererilor de servicii disciplinele de serviciu pot fi împărțite în discipline:
- modul unic;
- modul de grup;
- modul combinat.

Fig. 2.3.
În disciplinele de serviciu modul unic de fiecare dată pentru întreținere doar unul alocat o aplicație, pentru care cozile sunt revizuite după finalizarea serviciului aplicației anterioare.
În disciplinele de serviciu modul de grup de fiecare dată pentru întreținere este numit un grup de cereri o coadă, pentru care cozile sunt vizualizate numai după ce au servit toate solicitările de la un grup alocat anterior. Un grup de aplicații recent alocat poate include toate aplicațiile acestei cozi. Cereri de atribuire a serviciilor selectate secvențial din coadăși sunt deservite de dispozitiv, după care următorul grup de solicitări de la o altă coadă este atribuit pentru deservire în conformitate cu disciplina specificată de service.
Mod combinat - o combinație de moduri single și grup, atunci când o parte din cozile de aplicație sunt procesate în modul single și cealaltă parte în modul grup.
Disciplinele de servicii pot utiliza următoarele reguli de selectare a cererii de servicii.
Neprioritare (aplicațiile nu au privilegii pentru serviciile timpurii - preluarea resurselor):
- servicii de prim ajutor FIFO (primul în -să afară primul a intrat - primul a ieșit);
- service invers - aplicația este selectată din coadă în modul LIFO (ultimul în - mai întâi afară ultimul a intrat - primul a ieșit);
- serviciu aleatoriu - aplicația este selectată din coadă în modul Rand (aleatoriu - la întâmplare);
- întreținere ciclică - aplicațiile sunt selectate în timpul sondajului ciclic al driverelor din secvența 1, 2, NDIN N - numărul de acționări), după care se repetă secvența indicată;
Prioritate (aplicațiile au privilegii pentru serviciile timpurii - preluarea resurselor):
- din priorități relative - dacă în procesul de întreținere continuă a unei aplicații, aplicațiile cu priorități mai mari ajung în sistem, atunci deservirea unei aplicații curente, chiar și fără prioritate, nu este întreruptă, iar aplicațiile primite sunt trimise la coadă; prioritățile relative joacă un rol numai în momentul în care întreținerea curentă a aplicației este finalizată atunci când o nouă solicitare de serviciu este selectată din coadă.
- din priorități absolute - când se primește o aplicație cu prioritate ridicată, se întrerupe serviciul unei aplicații cu prioritate redusă, iar cererea primită este trimisă pentru serviciu; o cerere întreruptă poate fi returnată la coadă sau ștersă din sistem; dacă aplicația este returnată la coadă, atunci serviciul suplimentar al acesteia poate fi efectuat din loc întrerupt sau din nou;
- cu priorități mixte - restricțiile stricte asupra timpului de așteptare la coadă pentru deservirea aplicațiilor individuale necesită atribuirea de priorități absolute; în consecință, timpul de așteptare pentru aplicațiile cu priorități reduse poate fi inacceptabil de lung, deși aplicațiile individuale au o marjă de timp de așteptare; pentru a îndeplini restricțiile privind toate tipurile de aplicații, este posibil, împreună cu prioritățile absolute, să aloce priorități relative unor aplicații și să îl servească pe restul într-un mod care nu este prioritar;
- din alternarea priorităților - un analog al priorităților relative, prioritatea este luată în considerare numai în momentele în care serviciul curent al unui grup de solicitări de la o coadă este finalizat și un nou grup este alocat pentru serviciu;
- serviciu programat - aplicațiile din diferite clase (situate în unități diferite) sunt selectate pentru deservire conform unor programe care definesc secvența cozilor de anchetă, de exemplu, în cazul a trei clase de solicitări (unități), programul poate fi (2, 1, 3, 3, 1, 2) sau (1, 2, 3, 3, 2, 1).
În sistemele computerizate IM, de regulă, disciplina este implementată implicit FIFO Cu toate acestea, acestea au instrumente care oferă utilizatorului posibilitatea de a organiza disciplinele de serviciu necesare, inclusiv în program.
Aplicațiile primite în QS sunt împărțite în clase. În QS, care este un model matematic abstract, aplicațiile aparțin diferitelor clase în cazul în care acestea diferă cel puțin una dintre următoarele caracteristici în sistemul real simulat:
- durata serviciului;
- priorități.
Dacă cererile nu diferă în ceea ce privește durata serviciului și prioritățile, acestea pot fi depuse prin cereri din aceeași clasă, inclusiv la primirea din surse diferite.
Pentru descrierea matematică a disciplinelor serviciului cu priorități mixte se folosește matrice prioritară reprezentând o matrice pătrată Q \u003d (q,;), eu, j - 1, ..., I, I - numărul de clase de aplicații care intră în sistem.
Element q (j matricile stabilesc prioritatea cererilor de clasă eu în legătură cu aplicațiile de clasă; și poate lua următoarele valori:
- 0 - fără prioritate;
- 1 - prioritate relativă;
- 2 - prioritate absolută.
Elementele matricei prioritare trebuie să satisfacă următoarele cerinţe:
- q n \u003d 0, deoarece între aplicațiile din aceeași clasă nu pot fi stabilite priorități;
- în cazul în care un q (j \u003d 1 sau 2 atunci q^ \u003d 0, pentru că dacă clasa pretinde eu au prioritate față de aplicațiile clasei j atunci acestea din urmă nu pot avea prioritate asupra aplicațiilor de clasă eu (i, j \u003d 1, ..., I).
Depinzând de opțiuni de prioritizare în timpul funcționării sistemului, disciplinele prioritare de tamponare și servicii sunt împărțite în două clase:
- 1) cu priorități statice care nu se schimbă în timp;
- 2) cu priorități dinamice care se poate schimba în timpul funcționării sistemului în funcție de diverși factori, de exemplu, atunci când este atinsă o anumită valoare critică a lungimii de coadă a aplicațiilor unei clase care nu are prioritate sau are o prioritate scăzută, i se poate acorda o prioritate mai mare.
În sistemele de calculatoare IM există în mod necesar un singur element (obiect) prin care și numai prin intermediul acestuia, aplicațiile sunt introduse în model. În mod implicit, toate intrările introduse nu sunt prioritare. Există însă posibilități de atribuire a priorităților în secvența 1, 2, ..., inclusiv în timpul execuției modelului, adică. în dinamică.
Flux de ieșire - Acesta este un flux de aplicații deservite care părăsesc QS. În sistemele reale, aplicațiile trec prin mai multe QS: comunicare de tranzit, transportor de producție etc. În acest caz, fluxul de ieșire este fluxul de intrare pentru următorul QS.
Fluxul de intrare al primului QS, care trece prin QS ulterior, este denaturat, iar acest lucru complică modelarea analitică. Cu toate acestea, trebuie avut în vedere faptul că cu cel mai simplu flux de intrare și servicii exponențiale (acestea. în sistemele Markov) fluxul de ieșire este și cel mai simplu. Dacă timpul de serviciu are o distribuție neexponențială, atunci fluxul de ieșire este nu numai cel mai simplu, dar nu și recurent.
Rețineți că intervalele de timp dintre cererile pentru fluxul de ieșire nu sunt aceleași cu intervalele de servicii. La urma urmei, se poate dovedi că după terminarea următorului serviciu, QS este inactiv pentru o perioadă de timp din cauza lipsei de aplicații. În acest caz, intervalul fluxului de ieșire constă în timpul de repaus al QS și intervalul de serviciu al primei aplicații primite după oprire.
În QS, pe lângă fluxul de ieșire al aplicațiilor deservite, pot exista fluxul de aplicații nesolicitate. Dacă un flux recurent intră într-un astfel de QS și serviciul este exponențial, atunci fluxul de comenzi care nu sunt notificate este recurent.
Cozi de canale gratuite. În QS multicanal pot fi formate cozi de canale gratuite. Numărul de canale gratuite este o valoare aleatorie. Cercetătorii pot fi interesați de diferite caracteristici ale acestei variabile aleatorii. De obicei, acesta este numărul mediu de canale ocupate de serviciu în intervalul de studiu și factorii lor de încărcare.
După cum am menționat anterior, în obiectele reale, aplicațiile sunt deservite secvențial în mai multe QS.
Setul final de procesare QS interconectate secvențial pentru aplicațiile care circulă în ele se numește rețea de coadă (Semo) (Fig. 2.4, și).

Fig. 2.4.
CEMO este, de asemenea, numit qS multifazat.
Un exemplu de construire a unui SEMO IM pe care îl vom lua în considerare mai târziu.
Elementele principale ale CeMO sunt nodurile (U) și sursele (generatoare) de aplicații (G).
Nod Rețelele sunt un sistem în coadă.
Sursă - un generator de aplicații care intră în rețea și care necesită anumite etape de service în nodurile rețelei.
Pentru o imagine simplificată a CeMO, este utilizat un grafic.
Contele SeMO - grafic orientat (digraf), ale cărui vârfuri corespund nodurilor CeMO, iar arcurile reprezintă tranzițiile aplicațiilor între noduri (Fig. 2.4, b).
Deci, am examinat conceptele de bază ale QS. Însă, în dezvoltarea sistemelor de calcul IM și îmbunătățirea acestora, se folosește cu siguranță imensul potențial creativ, care este conținut în prezent în modelarea analitică a QS.
Pentru o mai bună percepție a acestui potențial creativ, ca primă aproximare, să ne bazăm pe clasificarea modelelor QS.
Destul de des, atunci când analizăm sistemele economice, este necesar să rezolvăm așa-numitele probleme de coadă care apar în următoarea situație. Să analizăm un sistem de întreținere a automobilului format dintr-un număr de stații de diferite capacități. La fiecare stație (element de sistem) pot apărea cel puțin două situații tipice:
- numărul de aplicații este prea mare pentru stația dată, apar cozi și trebuie să plătiți pentru întârzieri în serviciu;
- până la cerere se primesc prea puține cereri, iar acum este deja necesar să se țină seama de pierderile cauzate de timpul de oprire al stației.
Este clar că scopul analizei sistemului în acest caz este de a determina o oarecare corelație între pierderile de venituri datorate exploziile și pierderi datorate doar eu stații.
Teoria de coadă - O secțiune specială a teoriei sistemelor este o secțiune a teoriei probabilității în care sistemele de coadă sunt studiate folosind modele matematice.
Sistem de coadă (QS) - Acesta este un model care include: 1) un flux aleatoriu de cerințe, apeluri sau clienți care au nevoie de servicii; 2) un algoritm pentru implementarea acestui serviciu; 3) canale (dispozitive) pentru întreținere.
Exemple de QS sunt casele de bilete, benzinăriile, aeroporturile, vânzătorii, coaforii, medicii, centralele telefonice și alte facilități care deservesc anumite solicitări.
Problema teoriei în coadă constă în elaborarea recomandărilor pentru construcția rațională a QS și organizarea rațională a muncii lor, pentru a asigura o eficiență ridicată a serviciilor la costuri optime.
Principala caracteristică a sarcinilor acestei clase este dependența explicită a rezultatelor analizei și a recomandărilor primite asupra a doi factori externi: frecvența de primire și complexitatea comenzilor (și de aici momentul executării lor).
Obiectul teoriei în coadă este stabilirea unei relații între natura fluxului de aplicații, performanța unui canal de servicii individual, numărul de canale și eficiența serviciului.
La fel de caracteristici QS luate în considerare:
- procentul mediu de aplicații care sunt refuzate și nu lasă sistemul neatent;
- durata de oprire medie a canalelor individuale și a sistemului în ansamblu;
- timpul mediu de așteptare în linie;
- probabilitatea ca cererea să fie comunicată imediat;
- legea de distribuție a lungimii cozii și altele.
Adăugăm că aplicațiile (cerințele) vin la QS la întâmplare (la ore aleatorii), cu puncte de condensare și rarefecție. Timpul de serviciu al fiecărei cerințe este, de asemenea, aleatoriu, după care canalul de service este eliberat și este gata să îndeplinească următoarea solicitare. Fiecare QS, în funcție de numărul de canale și de performanța lor, are o anumită lățime de bandă. Randament QS poate absolut (numărul mediu de aplicații servite pe unitatea de timp) și relativ (raport mediu dintre numărul de cereri servit și numărul depuse)
3.1 Modele de sisteme de coadă.
Fiecare QS poate fi caracterizat prin expresia: (a / b / c): (d / e / f) Unde
a - distribuția fluxului de intrare al aplicațiilor;
b - distribuția fluxului de ieșire a aplicațiilor;
c - configurarea mecanismului de service;
d - disciplina cozii;
e - unitate de așteptare;
f - capacitatea sursei.
Acum luați în considerare mai detaliat fiecare caracteristică.
Flux de intrare de aplicații - numărul de aplicații primite în sistem. Se caracterizează prin intensitatea fluxului de intrare. l.
Flux de ieșire de aplicații - numărul de aplicații deservite de sistem. Se caracterizează prin intensitatea fluxului de ieșire. m.
configurarea sistemului implică numărul total de canale și noduri de servicii. QS poate conține:
- un canalservicii (o pistă, un vânzător);
- un canal de servicii, inclusiv mai multe noduri consecutive(sala de mese, clinica, transportor);
- mai multe canale de același tipservicii conectate în paralel (benzinărie, serviciu de anchetă, stație).
Astfel, se poate distinge QS monocanal și multicanal.
Pe de altă parte, dacă toate canalele de servicii din QS sunt ocupate, atunci aplicația abordată poate rămâne la coadă sau poate părăsi sistemul (de exemplu, Sberbank și o centrală telefonică). În acest caz, vorbim despre sisteme cu coadă (așteptare) și sisteme cu eșecuri.
Coadă - Acesta este un set de aplicații primite în sistem pentru repararea și așteptarea reparației. O coadă se caracterizează prin lungimea cozii și disciplina ei.
Linia de disciplină - Aceasta este o regulă pentru deservirea aplicațiilor din coadă. Principalele tipuri de cozi includ următoarele:
- PERPPO (primul venit - primul servit) - tipul cel mai frecvent;
- POSPPO (ultimul care vine - primul care a fost servit);
- POP (selecție aleatorie de aplicații) - de la banca de date.
- PR - serviciu prioritar
Lungimea cozii poate
- nelimitat - atunci vorbesc despre un sistem cu așteptare pură;
- egal cu zero - atunci vorbesc despre un sistem cu eșecuri;
- lungime limitată (sistem de tip mixt).
Bloc de așteptare - „capacitatea” sistemului - numărul total de aplicații din sistem (în linie și în service). Prin urmare, e \u003d c +d.
Capacitatea surseigenerarea de solicitări de servicii este numărul maxim de aplicații care pot fi primite de QS. De exemplu, la aeroport, capacitatea sursei este limitată de numărul tuturor aeronavelor existente, iar capacitatea sursei schimbului telefonic este egală cu numărul de locuitori ai Pământului, adică. poate fi considerat nelimitat.
Numărul de modele QS corespunde numărului de combinații posibile ale acestor componente.
3.2 Fluxul de intrare al cerințelor.
Cu fiecare perioadă de timp [ a, a+ T ], asociem o variabilă aleatorie Xegal cu numărul de cerințe primite în sistem de-a lungul timpului T.
Fluxul de apel a fost apelat staționardacă legea distribuției este independentă de punctul de plecare al decalajului și, dar depinde doar de lungimea acestui decalaj T. De exemplu, fluxul de aplicații pentru un schimb telefonic în timpul zilei ( T\u003d 24 de ore) nu poate fi considerat staționar, dar de la 13 la 14 ore ( T\u003d 60 minute) - este posibil.
Stream apelat fără aftereffectdacă istoricul fluxului nu afectează primirea cerințelor în viitor, adică cerințele sunt independente unele de altele.
Stream apelat comundacă într-o perioadă foarte scurtă de timp nu pot intra în sistem mai mult de o cerință. De exemplu, fluxul către coafor este obișnuit, dar nu și la oficiul registrului. Dar, dacă ca o variabilă aleatoare X ia în considerare perechi de aplicații primite de biroul de registru, atunci un astfel de flux va fi obișnuit (adică, uneori, un flux extraordinar poate fi redus la obișnuit).
Stream apelat cel mai simplu dacă este staționar, fără afecțiuni și obișnuit.
Teorema principală. Dacă debitul este cel mai simplu, atunci r.v. X [a. a + T ] este distribuit conform legii lui Poisson, adică .
Corolarul 1. Cel mai simplu flux se numește și flux Poisson.
Corolarul 2. M(X)= M(X [ a , a + T ] )= lT, adică pe parcursul T lT aplicații. În consecință, pentru o unitate de timp, media l aplicații. Această cantitate se numește intensitate flux de intrare.
Luați în considerare un EXEMPLU .
Studioul primește în medie 3 aplicații pe zi. Având în vedere că fluxul este cel mai simplu, găsiți probabilitatea ca în următoarele două zile numărul de aplicații să fie de cel puțin 5.
Decizie.
În funcție de starea problemei, l=3, T\u003d 2 zile, intrare Poisson, n
³5. atunci când decideți, este convenabil să introduceți evenimentul opus, constând în faptul că în timpul Tmai puțin de 5 cereri vor fi primite. Prin urmare, conform formulei Poisson, obținem 
^
3.3 Starea sistemului Grafic matricial și tranziție.
Într-un moment aleatoriu în timp, QS se deplasează de la o stare la alta: numărul de canale ocupate, numărul de solicitări și cozi etc. se schimbă. Astfel, QS cu n canale și lungimea cozii egală cu m, poate fi într-una din următoarele state:
E 0 - toate canalele sunt gratuite;
E 1 - un canal este ocupat;
E n - toate canalele sunt ocupate;
E n +1 - toate canalele sunt ocupate și o singură aplicație în coadă;
E n + m - toate canalele și toate locurile din coadă sunt ocupate.
Un sistem similar cu eșecuri pot fi în state E 0 – E n .
Pentru QS cu așteptare pură, există un număr infinit de state. Prin urmare, stat E n QS la timp t Este cantitatea n aplicațiile (cerințele) care sunt în sistem la un moment dat, adică n= n(t) - valoare aleatorie, E n (t) - rezultatele acestei variabile aleatorii și P n (t) - probabilitatea ca sistemul să fie într-o stare E n .
Suntem deja familiarizați cu starea sistemului. Rețineți că nu toate stările sistemului sunt echivalente. Se numește starea sistemului sursadacă sistemul poate ieși din această stare, dar nu se poate întoarce la el. Se numește starea sistemului izolat dacă sistemul nu poate ieși din această stare sau intra în ea.
Pentru claritate, imaginile stărilor de sistem folosesc scheme (așa-numitele grafice de tranziție), în care săgețile indică tranzițiile posibile ale sistemului de la o stare la alta, precum și probabilitățile unor astfel de tranziții.

Figura 3.1 - grafic de tranziție
| Comp. | E 0 | E 1 | E 2 | |
| E 0 | P 0,0 | P 0,1 | P 0,2 | |
| E 1 | P 1.0 | R 1.1 | R 1,2 | |
| E 2 | P 2.0 | R 2.2 | R 2.2 |
Uneori este convenabil să folosiți matricea de tranziție. În acest caz, prima coloană indică starea inițială a sistemului (curent) și apoi sunt date probabilitățile de trecere de la aceste stări la altele.
Din moment ce sistemul va trece cu siguranță de la unul
stat la altul, atunci suma probabilităților din fiecare rând este întotdeauna egală cu una.
3.4 QS cu un singur canal.
3.4.1 QS cu un singur canal cu eșecuri.
Vom lua în considerare sistemele care satisfac cerințele din:
(P / E / 1): (- / 1 / ¥). Să presupunem, de asemenea, că timpul de furnizare a unei solicitări nu depinde de numărul de solicitări primite în sistem. În continuare, „P” înseamnă că fluxul de intrare este distribuit în conformitate cu legea lui Poisson, adică. cel mai simplu, „E” înseamnă că fluxul de ieșire este distribuit exponențial. De asemenea, în continuare, formulele principale sunt date fără dovezi.
Pentru un astfel de sistem, sunt posibile două state: E 0 - sistemul este gratuit și E 1 - Sistemul este ocupat. Compunem matricea de tranziție. Lua Dt - o perioadă de timp infinit de mică. Fie ca evenimentul A să constea în faptul că sistemul în timp Dt O cerere a fost primită. Evenimentul B este acela în timp Dt O cerință este îndeplinită. Eveniment ȘI eu , k - pe parcursul Dt sistemul va trece de la stat E eu a afirma E k . La fel de l - intensitatea fluxului de intrare, apoi în timp Dt intră în sistem în medie l * Dt cerințe. Adică, probabilitatea unei cereri P (A) \u003deu * Dtși probabilitatea evenimentului opus P (Ā) \u003d 1-l * Dt. P (B) \u003dF(Dt)= P(b< D t)=1- e - m D t = m Dt - probabilitatea de a furniza cererea la timp Dt. Apoi A 00 - cererea nu va fi primită sau va fi primită, dar va fi comunicată. A 00 \u003d Ā + A * B. P 00 \u003d 1 - l * Dt. (am luat în considerare că (Dt) 2 - valoare infinitesimală)
Și 01 - cererea va fi primită, dar nu va fi comunicată. A 01 \u003d A *
 . P 01 =
l * Dt.
. P 01 =
l * Dt.
Și 10 - cererea va fi servită și nu va fi nouă. A 10 \u003d B * A. P 10 = m * Dt.
Și 11 - cererea nu va fi notificată sau va fi primită una nouă care nu a fost încă comunicată. A 11 \u003d + B *
A. P 01 \u003d 1-
m * Dt.
Astfel, obținem matricea de tranziție:
| Comp. | E 0 | E 1 |
| E 0 | 1-l * Dt | l * Dt |
| E 1 | m * Dt | 1-m * Dt |
Probabilitatea de întreruperi și eșecul sistemului.
Acum găsim probabilitatea ca sistemul să fie în stare E 0
la orice moment dat t (acestea. r 0
(
t)
) Grafic funcțional  în figura 3.2.
în figura 3.2.
Asimptotul graficului este drept  .
.
Evident, începând la un moment dat t, 

1
Figura 3.2
În sfârșit, obținem asta și  Unde r 1
(t)
- probabilitatea ca la un moment dat t
sistemul este ocupat (adică este în stare E 1
).
Unde r 1
(t)
- probabilitatea ca la un moment dat t
sistemul este ocupat (adică este în stare E 1
).
Evident, la începutul operațiunii QS, procesul în curs nu va fi staționar: va fi un mod „tranzitoriu”, care nu este staționar. După o perioadă de timp (care depinde de intensitățile fluxului de intrare și ieșire), acest proces se va stinge și sistemul va trece într-un mod de funcționare staționar, în stare constantă, iar caracteristicile probabilității nu vor mai depinde de timp.
Modul de funcționare staționar și factorul de încărcare a sistemului.
Dacă probabilitatea ca sistemul să fie în stare E k , adică R k (t),
independent de timp t, atunci ei spun că a fost stabilit în QS modul staționar muncă. În acest caz, valoarea  denumit factorul de încărcare a sistemului (sau densitate redusă a fluxului de aplicare). Apoi pentru probabilități r 0
(t)
și r 1
(t)
obținem următoarele formule:
denumit factorul de încărcare a sistemului (sau densitate redusă a fluxului de aplicare). Apoi pentru probabilități r 0
(t)
și r 1
(t)
obținem următoarele formule:  ,
,  . De asemenea, putem concluziona: cu cât este mai mare factorul de încărcare a sistemului, cu atât este mai mare probabilitatea unei defecțiuni a sistemului (adică probabilitatea ca sistemul să fie ocupat).
. De asemenea, putem concluziona: cu cât este mai mare factorul de încărcare a sistemului, cu atât este mai mare probabilitatea unei defecțiuni a sistemului (adică probabilitatea ca sistemul să fie ocupat).
La spălarea auto, o unitate pentru întreținere. Mașinile ajung la o distribuție Poisson cu o intensitate de 5 mașini / oră. Timpul mediu de service pentru o mașină este de 10 minute. Găsiți probabilitatea ca o mașină care ajunge să găsească sistemul ocupat dacă QS funcționează în regim staționar.
Decizie. În funcție de starea problemei, l=5, m y
\u003d 5/6. Trebuie să găsești probabilitatea r 1
- probabilitatea eșecului sistemului.  .
.
3.4.2 QS cu un singur canal cu lungime nelimitată de coadă.
Vom lua în considerare sistemele care satisfac cerințele: (P / E / 1) :( d / ¥ / ¥). Sistemul poate fi într-una din state E 0 , …, E k , ... Analiza arată că, după un timp, un astfel de sistem începe să funcționeze în modul staționar dacă intensitatea fluxului de ieșire depășește intensitatea fluxului de intrare (adică factorul de încărcare al sistemului este mai mic decât unul). Având în vedere această condiție, obținem sistemul de ecuații
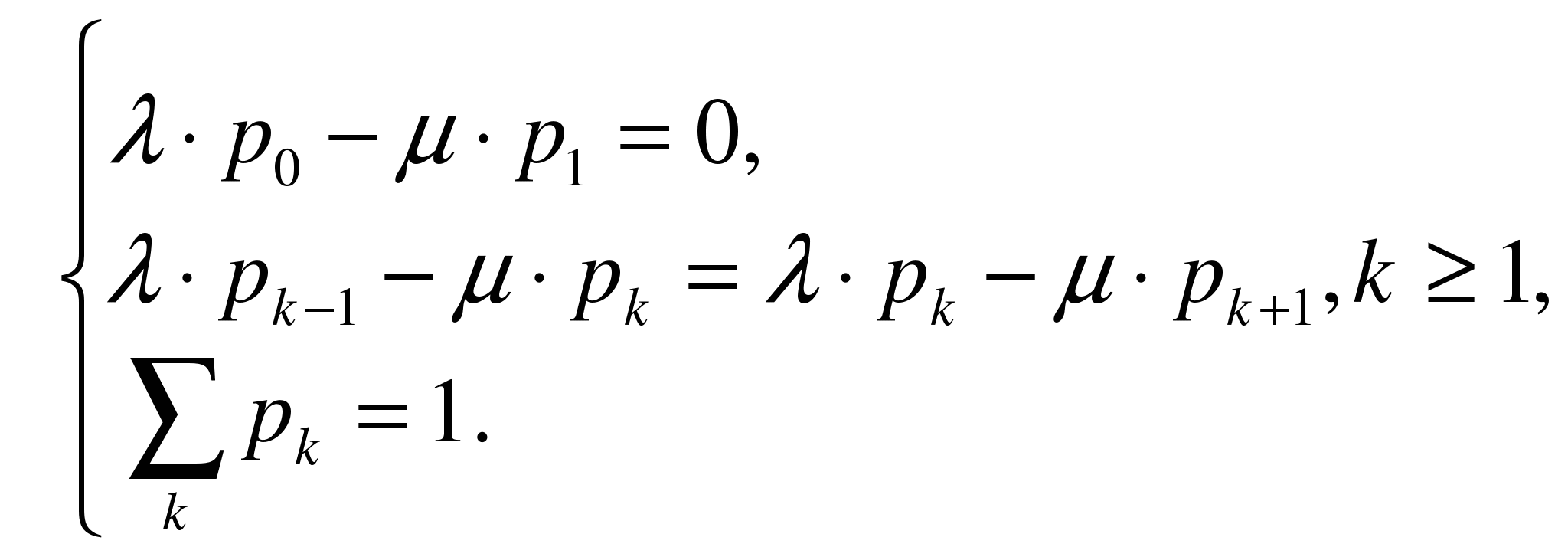
rezolvând care găsim asta. Astfel, cu condiția ca y<1, получим 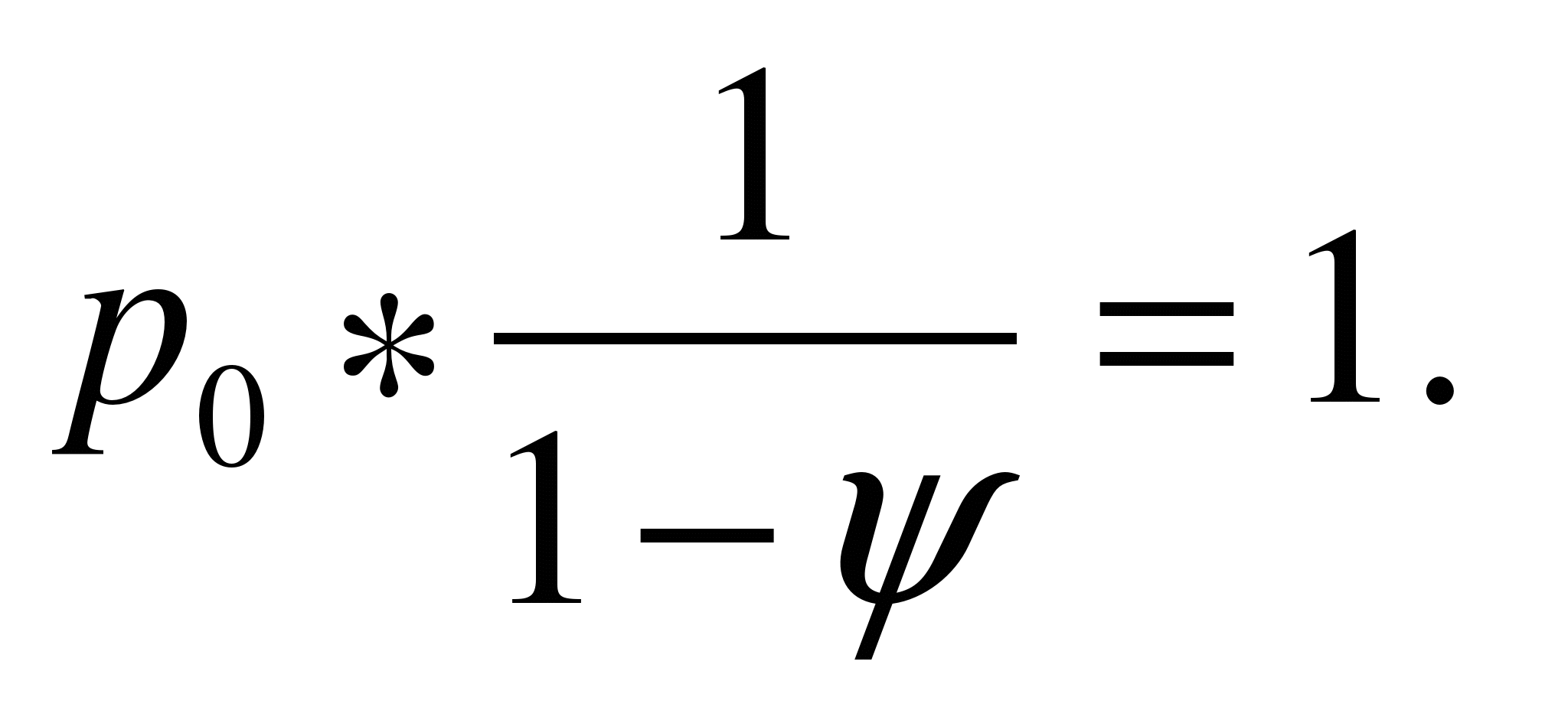 In cele din urma,
In cele din urma,  și
și  - probabilitatea de a găsi un QS într-o stare E k la un moment dat la întâmplare.
- probabilitatea de a găsi un QS într-o stare E k la un moment dat la întâmplare.
Performanța medie a sistemului.
Datorită primirii neuniforme a cerințelor din sistem și a fluctuațiilor timpului de serviciu, în sistem este formată o coadă. Pentru un astfel de sistem, puteți explora:
- n - numărul de cerințe în QS (în linie și în serviciu);
- v - lungimea cozii;
- w - timpul de așteptare pentru începerea serviciului;
- w 0 - timpul total petrecut în sistem.
Vom fi interesați caracteristici medii (adică, luăm așteptarea matematică de la variabilele aleatorii luate în considerare și ne amintim că y<1).
 - numărul mediu de aplicații din sistem.
- numărul mediu de aplicații din sistem.
 - lungimea medie a cozii.
- lungimea medie a cozii.
 - timpul mediu de așteptare pentru începerea serviciului, adică. timpul de așteptare în linie.
- timpul mediu de așteptare pentru începerea serviciului, adică. timpul de așteptare în linie.
 - timpul mediu pe care aplicația îl petrece în sistem - în linie și în service.
- timpul mediu pe care aplicația îl petrece în sistem - în linie și în service.
La spălarea auto, există o unitate pentru întreținere și există un loc pentru o coadă. Mașinile ajung la o distribuție Poisson cu o intensitate de 5 mașini / oră. Timpul mediu de service pentru o mașină este de 10 minute. Găsiți toate caracteristicile medii ale QS.
Decizie. l=5, m \u003d 60min / 10min \u003d 6. Factor de încărcare y
\u003d 5/6. Apoi numărul mediu de mașini din sistem  lungimea medie a cozii
lungimea medie a cozii  , timpul mediu de așteptare pentru începerea serviciului
, timpul mediu de așteptare pentru începerea serviciului  ore \u003d 50 min și, în final, timpul mediu petrecut în sistem
ore \u003d 50 min și, în final, timpul mediu petrecut în sistem  ora.
ora.
3.4.3 QS de tip mixt cu un singur canal.
Presupunem că lungimea cozii este m cerințe. Apoi, pentru orice s£
m, probabilitatea de a găsi QS într-o stare E 1+
s calculat după formulă  , adică o cerere este servită și alta s aplicații - în linie.
, adică o cerere este servită și alta s aplicații - în linie.
Probabilitatea de oprire este  ,
,
iar probabilitatea eșecului sistemului este  .
.
Se dau trei sisteme cu un singur canal pentru fiecare l=5, m \u003d 6. Dar primul sistem - cu eșecuri, al doilea - cu așteptare pură și al treilea - cu o lungime limitată de coadă, m\u003d 2. Găsiți și comparați probabilitățile de oprire ale acestor trei sisteme.
Decizie. Pentru toate sistemele, factorul de încărcare y \u003d 5/6. Pentru un sistem cu eșecuri  . Pentru un sistem pur de așteptare
. Pentru un sistem pur de așteptare 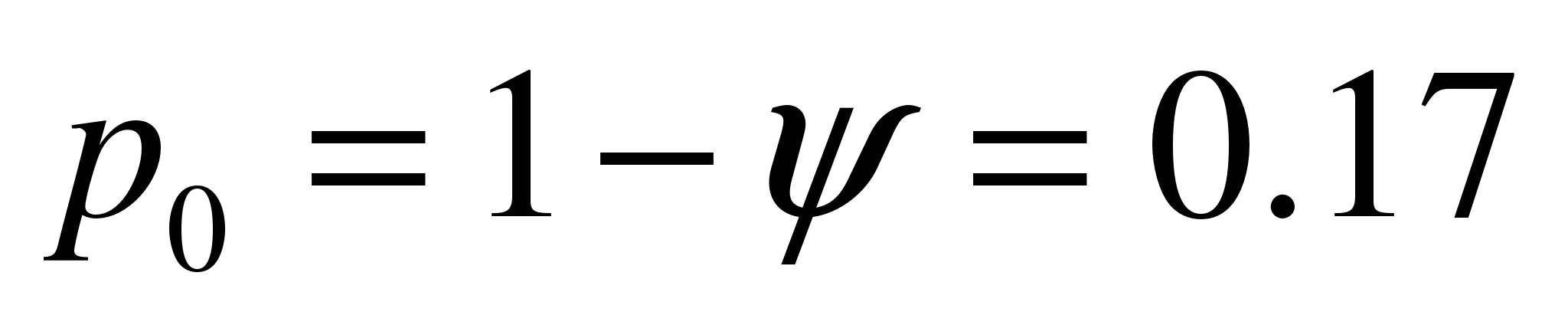 . Pentru un sistem cu o lungime limitată de coadă
. Pentru un sistem cu o lungime limitată de coadă  . Concluzia este evidentă: cu cât sunt mai multe solicitări în coadă, cu atât este mai mică probabilitatea ca timpul de oprire al sistemului.
. Concluzia este evidentă: cu cât sunt mai multe solicitări în coadă, cu atât este mai mică probabilitatea ca timpul de oprire al sistemului.
3.5 QS multicanal.
3.5.1 QS multicanal cu defecțiuni.
Vom lua în considerare sistemele (P / E / s): (- / s / ¥) sub presupunerea că timpul de serviciu este independent de fluxul de intrare și toate liniile funcționează independent. Sistemele multicanal, pe lângă factorul de încărcare, pot fi caracterizate și prin coeficient  Unde s - numărul de canale de servicii. Studiind QS multicanal, obținem următoarele formule (formule Erlang) pentru probabilitatea de a găsi sistemul într-o stare E k la un moment dat la întâmplare:
Unde s - numărul de canale de servicii. Studiind QS multicanal, obținem următoarele formule (formule Erlang) pentru probabilitatea de a găsi sistemul într-o stare E k la un moment dat la întâmplare:
 , k \u003d 0, 1, ...
, k \u003d 0, 1, ...
Funcția de cost.
În ceea ce privește sistemele cu un singur canal, o creștere a factorului de încărcare duce la o creștere a probabilității de defectare a sistemului. Pe de altă parte, o creștere a numărului de linii de servicii duce la o creștere a probabilității de oprire a sistemului sau a canalelor individuale. Astfel, este necesar să găsiți numărul optim de canale de service pentru acest QS. Numărul mediu de linii de servicii gratuite poate fi găsit după formulă  . Introducem C ( s) – funcția de cost QS dependent din 1
- costul unui refuz (penalizare pentru o cerere restantă) și din din 2
- costul timpului de oprire al unei linii pe unitatea de timp.
. Introducem C ( s) – funcția de cost QS dependent din 1
- costul unui refuz (penalizare pentru o cerere restantă) și din din 2
- costul timpului de oprire al unei linii pe unitatea de timp.
Pentru a căuta cea mai bună opțiune, trebuie să găsiți (și aceasta se poate face) valoarea minimă a funcției de cost: DIN(s) \u003d s 1*
l *
p s + s 2*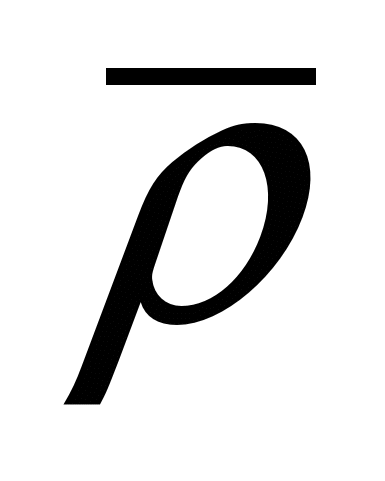 , al cărui grafic este prezentat în figura 3.3:
, al cărui grafic este prezentat în figura 3.3:

Figura 3.3
Căutarea valorii minime a funcției de cost este aceea că pentru prima dată le găsim valorile s \u003d 1, apoi pentru s \u003d 2, apoi pentru s \u003d 3 etc. până la un anumit pas valoarea funcției C ( s) nu va fi mai mare decât precedentul. Aceasta înseamnă că funcția a atins minimul și a început să crească. Răspunsul este că numărul de canale de serviciu (valoare s) pentru care funcția de cost este minimă.
EXEMPLU .
Câte linii de servicii trebuie să conțină un QS cu eșecuri dacă l\u003d 2 treb / \u200b\u200boră m \u003d 1 treb / \u200b\u200boră, penalitatea pentru fiecare defecțiune este de 7 mii de ruble, costul timpului de oprire al unei linii este de 2 mii de ruble. în oră?
Decizie. y = 2/1=2. din 1 =7, din 2 =2.
Presupunem că QS are două canale de servicii, adică. s
\u003d 2. Apoi  . Prin urmare, C (2) \u003d s 1
* l *p 2
+ s 2
*(2-
tu *(1-r 2
))
= =7*2*0.4+2*(2-2*0.6)=7.2.
. Prin urmare, C (2) \u003d s 1
* l *p 2
+ s 2
*(2-
tu *(1-r 2
))
= =7*2*0.4+2*(2-2*0.6)=7.2.
Să pretindem asta s
\u003d 3. Apoi 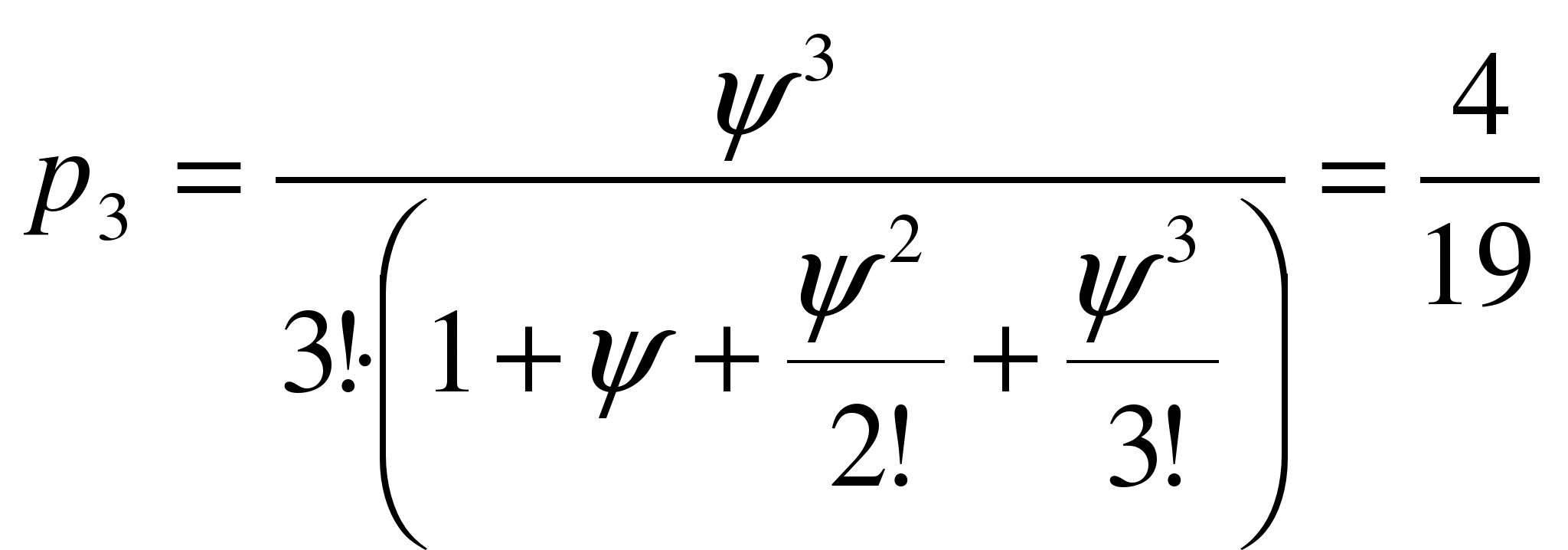 , C (3) \u003d s 1
* l *p 3
+ s 2
*
, C (3) \u003d s 1
* l *p 3
+ s 2
*
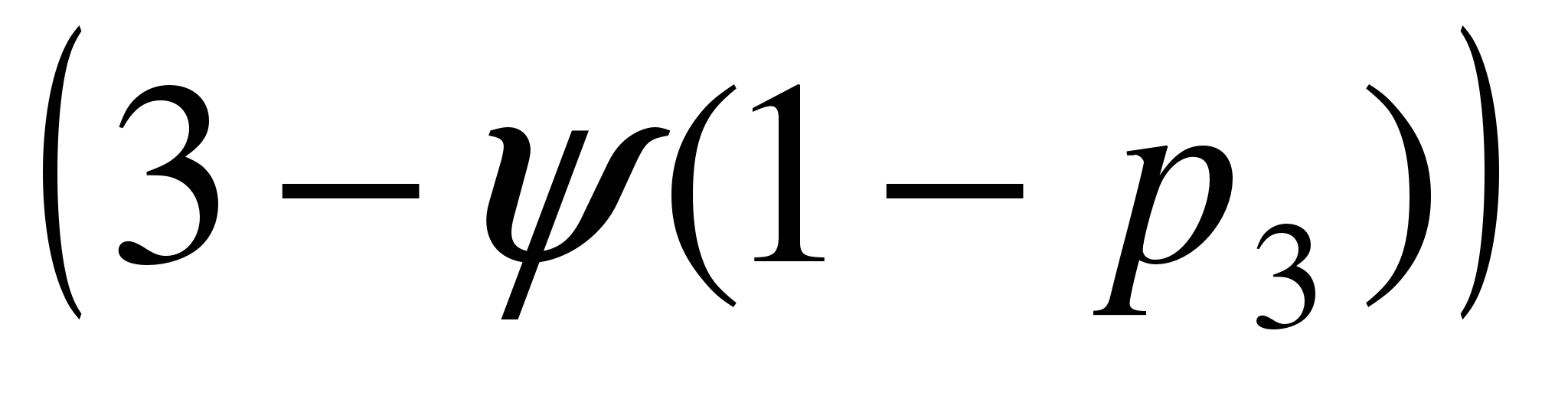 =5.79.
=5.79.
Să presupunem că există patru canale, adică. s
\u003d 4. Apoi  ,
,  , C (4) \u003d s 1
* l *p 4
+ s 2
*
, C (4) \u003d s 1
* l *p 4
+ s 2
*
 =5.71.
=5.71.
Presupunem că QS are cinci canale de servicii, adică. s
\u003d 5. Apoi  , C (5) \u003d6.7 este mai mare decât valoarea anterioară. Prin urmare, numărul optim de canale de servicii este de patru.
, C (5) \u003d6.7 este mai mare decât valoarea anterioară. Prin urmare, numărul optim de canale de servicii este de patru.
3.5.2 QS multicanal cu coadă.
Vom lua în considerare sistemele (P / E / s) :( d / d + s / ¥), cu presupunerea că timpul de serviciu este independent de fluxul de intrare și toate liniile funcționează independent. Spunem că sistemul este instalat funcționare staționarădacă numărul mediu de solicitări primite este mai mic decât numărul mediu de cerințe servite pe toate liniile sistemului, adică. l
P (w\u003e 0)
- probabilitatea de așteptare pentru începerea serviciului;  .
.
Această din urmă caracteristică ne permite să rezolvăm problema determinării numărului optim de canale de serviciu, astfel încât probabilitatea de așteptare pentru pornirea serviciului să fie mai mică decât un număr dat. Pentru a face acest lucru, este suficient să se calculeze probabilitatea de a aștepta secvențial s =1, s =2, s\u003d 3 etc.
EXEMPLU .
SMO este o stație de ambulanță dintr-un microdistrict mic. l\u003d 3 apeluri pe oră și m \u003d 4 apeluri pe oră pentru o echipă. Câte brigade trebuie să ai la stație, astfel încât probabilitatea de așteptare la plecare să fie mai mică de 0,01?
Decizie. Factorul de încărcare a sistemului y
\u003d 0,75. Să presupunem că există două echipe în prezență. Găsiți probabilitatea de așteptare pentru începerea serviciului când s =2.  ,
,  .
.
Să presupunem că există trei echipe, adică. s \u003d 3. Prin formulele obținem asta r 0 \u003d 8/17, P (w>0)=0.04>0.01 .
Să presupunem că la gară există patru brigăzi, adică. s \u003d 4. Atunci obținem asta r 0 \u003d 416/881, P (w>0)=0.0077<0.01 . Prin urmare, stația ar trebui să aibă patru echipe.
3.6 Întrebări pentru autocontrol
- Subiectul și sarcinile teoriei în coadă.
- QS, modelele și denumirile lor.
- Fluxul de intrare a cerințelor. Intensitatea fluxului de intrare.
- Starea sistemului. Grafic matricial și tranziție.
- QS cu un singur canal cu eșecuri.
- QS cu un singur canal cu coadă. Specificații.
- Mod de operare staționar. Factorul de încărcare a sistemului.
- QS multicanal cu defecțiuni.
- Optimizarea funcției de cost.
- QS multicanal cu coadă. Specificații.
3.7 Exerciții pentru muncă independentă
- Snack bar-ul de la benzinărie are un contor. Mașinile sosesc conform distribuției Poisson, în medie 2 mașini în 5 minute. În medie, 1,5 minute sunt suficiente pentru a finaliza comanda, deși durata serviciului este distribuită exponențial. Găsiți: a) probabilitatea perioadei de oprire a contorului; b) performanța medie; c) probabilitatea ca numărul de autoturisme sosite să fie de minim 10.
- Aparatul cu raze X vă permite să examinați, în medie, 7 persoane pe oră. Intensitatea vizitatorilor este de 5 persoane pe oră. Presupunând funcționarea staționară, determinați caracteristicile medii.
- Timpul de serviciu în QS este supus legii exponențiale,
m \u003d 7 cerințe pe oră. Găsiți probabilitatea ca a) timpul de serviciu să fie cuprins între 3 și 30 de minute; b) cererea va fi comunicată în termen de o oră. Utilizați tabelul valorilor funcțiilor e x . - În portul râului există o dană, intensitatea debitului de intrare este de 5 nave pe zi. Intensitatea de încărcare și descărcare este de 6 nave pe zi. Ținând cont de modul de funcționare staționar, determinați toate caracteristicile medii ale sistemului.
- l=3, m \u003d 2, penalitatea pentru fiecare defecțiune este de 5, iar costul timpului de oprire al unei linii este de 2?
- Care este numărul optim de canale de servicii pe care ar trebui să le aibă QS dacă l=3, m \u003d 1, penalitatea pentru fiecare defecțiune este de 7, iar costul timpului de oprire al unei linii este de 3?
- Care este numărul optim de canale de servicii pe care ar trebui să le aibă QS dacă l=4, m \u003d 2, penalitatea pentru fiecare defecțiune este de 5, iar costul timpului de oprire al unei linii este de 1?
- Determinați numărul pistelor pentru aeronave, ținând cont de cerința că probabilitatea de așteptare ar trebui să fie mai mică de 0,05. În același timp, intensitatea fluxului de intrare este de 27 de aeronave pe zi, iar intensitatea serviciului lor este de 30 de aeronave pe zi.
- Câte linii transportoare independente echivalente ar trebui să aibă atelierul pentru a asigura un ritm de lucru la care probabilitatea de așteptare pentru prelucrarea produselor ar trebui să fie mai mică de 0,03 (fiecare produs este produs într-o linie). Se știe că intensitatea primirii comenzilor de 30 de produse pe oră și intensitatea procesării unui produs într-o linie este de 36 de produse pe oră.
- O variabilă continuă aleatorie X este distribuită conform unei legi exponențiale cu parametrul l \u003d 5. Găsiți funcția de distribuție, caracteristicile și probabilitatea de a atinge un r.v. X în intervalul de la 0,17 la 0,28.
- Numărul mediu de apeluri care ajung la PBX într-un minut este 3. Având în vedere că fluxul este Poisson, găsiți probabilitatea ca apelul să ajungă în 2 minute: a) două apeluri; b) mai puțin de două apeluri; c) cel puțin două apeluri.
- În cutie există 17 părți, dintre care 4 sunt defecte. Selectorul extrage la întâmplare 5 părți. Găsiți probabilitatea ca a) toate părțile extrase să fie de înaltă calitate; b) dintre părțile extrase, 3 sunt defecte.
- Câte canale trebuie să aibă un QS cu eșecuri dacă l\u003d 2 treb / \u200b\u200boră m\u003d 1 treb / \u200b\u200boră, penalitatea pentru fiecare defecțiune este de 8t.rub., Costul timpului de oprire al unei linii este de 2t.rub. în oră?
Exemple de soluționare a problemelor sistemelor de coadă
Este necesară rezolvarea problemelor 1-3. Datele sursă sunt prezentate în tabel. 2-4.
Câteva notații utilizate în teoria cozii pentru formule:
n este numărul de canale din QS;
λ este intensitatea fluxului de intrare al aplicațiilor P în;
v este intensitatea fluxului de ieșire al aplicațiilor P o;
μ este intensitatea fluxului de servicii P aproximativ;
ρ este un indicator al încărcării sistemului (trafic);
m - numărul maxim de locuri din coadă, limitând lungimea cozii de aplicații;
i este numărul de surse de aplicații;
p to - probabilitatea stării a k-a a sistemului;
p o - probabilitatea de oprire a întregului sistem, adică probabilitatea ca toate canalele să fie libere;
p sist - probabilitatea acceptării aplicației în sistem;
p open - probabilitatea refuzului unei cereri de a o accepta în sistem;
p despre - probabilitatea ca cererea să fie comunicată;
A - rata absolută a sistemului;
Q este debitul relativ al sistemului;
pts - numărul mediu de aplicații din coadă;
aproximativ - numărul mediu de cereri prestate;
sist - numărul mediu de aplicații din sistem;
pts - timpul mediu de așteptare pentru o aplicație în coadă;
aproximativ - timpul mediu de servire a cererii, referindu-se doar la aplicațiile notificate;
sis - timpul mediu de ședere al cererii în sistem;
ozh - timpul mediu care limitează așteptarea unei aplicații în coadă;
- numărul mediu de canale ocupate.
Rata absolută de QS A - numărul mediu de solicitări, can sistemul poate servi pe unitate de timp.
Randamentul relativ al QS Q este raportul dintre numărul mediu de solicitări furnizate de sistem pe unitatea de timp și numărul mediu de solicitări primite în acest timp.
Atunci când rezolvați problemele de coadă, este extrem de important să respectați următoarea secvență:
1) determinarea tipului de QS conform tabelului. 4.1;
2) alegerea formulelor în conformitate cu tipul QS;
3) soluția problemei;
4) formularea concluziilor asupra problemei.
1. Schema morții și a reproducerii. Știm că cu un grafic de stare etichetat la dispoziția noastră, putem scrie cu ușurință ecuațiile Kolmogorov pentru probabilitățile de stat, precum și scrie și rezolva ecuații algebice pentru probabilitățile finale. Merită spus că, în unele cazuri, ultimele ecuații au succes

decide în avans, în formă de scrisoare. În special, acest lucru se poate face dacă graficul de stare al sistemului este așa-numita „schemă a morții și a reproducerii”.
Graficul de stare pentru schema decesului și reproducere are forma prezentată în Fig. 19.1. Particularitatea acestui grafic este aceea că toate stările sistemului pot fi extinse într-un singur lanț în care fiecare dintre stările mijlocii ( S 1 , S 2 , ..., S n-1) este conectat printr-o săgeată înainte și înapoi cu fiecare dintre statele vecine - dreapta și stânga și stările extreme (S 0 , S n) - cu o singură stare adiacentă. Termenul „schemă a morții și reproducerii” provine din sarcini biologice, unde o modificare a dimensiunii populației este descrisă de o schemă similară.
Schema morții și a reproducerii se găsește foarte des în diferite probleme de practică, în special - în teoria cozii, în legătură cu aceasta este util, o dată pentru totdeauna, să găsim probabilitățile finale ale statelor pentru aceasta.
Să presupunem că toate fluxurile de evenimente care traduc sistemul de-a lungul săgeților graficului sunt cele mai simple (pentru scurtitate, vom numi și sistemul S și procesul care se desfășoară în el - cel mai simplu).
Folosind graficul din fig. 19.1, compunem și rezolvăm ecuații algebrice pentru probabilitățile finale ale statului), existența rezultă din faptul că de la fiecare stare putem merge una la cealaltă, la numărul de state, desigur). Pentru primul stat S 0 avem:
![]() (19.1)
(19.1)
Pentru a doua stare S 1:
În virtutea (19.1), ultima egalitate se reduce la formă
![]()
![]()
![]()
unde k ia toate valorile de la 0 la p. Deci, probabilitățile finale p 0, p 1,..., p n satisfac ecuațiile
 (19.2)
(19.2)
în plus, trebuie luată în considerare condiția de normalizare
p 0 + p 1 + p 2 +…+ p n \u003d 1. (19,3)
Rezolvăm acest sistem de ecuații. Din prima ecuație (19.2) ne exprimăm p 1 prin r 0 :
p 1 = p 0. (19.4)
Din a doua, luând în considerare (19.4), obținem:
![]() (19.5)
(19.5)
‣‣‣ din a treia, luând în considerare (19,5),
![]() (19.6)
(19.6)
și, în general, pentru oricare k (de la 1 la n):
![]() (19.7)
(19.7)
Acordăm atenție formulei (19.7). Numerotatorul este produsul tuturor intensităților la săgețile care duc de la stânga la dreapta (de la început până la această stare S k) și în numitor - produsul tuturor intensităților care stau la săgețile care duc de la dreapta la stânga (de la început până la S k).
Τᴀᴋᴎᴍ ᴏϬᴩᴀᴈᴏᴍ, toate probabilitățile de stare r 0 , p 1 , ..., p n exprimat prin una dintre ele ( r 0). Înlocuim aceste expresii în condiția de normalizare (19.3). Primim, scoatem paranteza r 0:
de aici obținem expresia pentru r 0 :
(am ridicat paranteza la puterea de -1, pentru a nu scrie fracții cu două punți). Toate celelalte probabilități sunt exprimate în termeni de r 0 (a se vedea formulele (19.4) - (19.7)). Rețineți că coeficienții de r 0 în fiecare dintre ei nu este altceva decât membri consecutivi ai seriei care stau după unitatea din formulă (19.8). De aici, calcularea r 0 , am găsit deja toți acești coeficienți.
Formulele obținute sunt foarte utile în rezolvarea celor mai simple probleme ale teoriei de la coadă.
^ 2. Formula lui Little. Acum vom deduce o formulă importantă care raportează (pentru limitarea stării staționare) numărul mediu de aplicații L un sistem localizat în sistemul de coadă (de exemplu, deservit sau în linie) și timpul mediu în care o aplicație rămâne în sistem W autoc.
Luați în considerare orice QS (un singur canal, multi-canal, Markov, non-Markov, cu o coadă nelimitată sau limitată) și două fluxuri de evenimente asociate acestuia: fluxul de aplicații care sosesc la QS și fluxul de aplicații care părăsesc QS. Dacă sistemul are o stare staționară limită, atunci numărul mediu de solicitări care sosesc în QS pe unitate de timp este egal cu numărul mediu de solicitări care îl părăsesc: ambele fluxuri au aceeași intensitate λ.
Denota: X (t) - numărul de aplicații care au ajuns la QS înainte t. Y(t) - numărul de aplicații părăsite QS

până în momentul în care t. Ambele funcții sunt aleatorii și se schimbă brusc (crește cu una) la momentul sosirii aplicațiilor (X(t)) și părăsirea aplicațiilor (YT)). Tipul funcției X (t) și Y (t) prezentat în fig. 19,2; ambele linii sunt în trepte, sus - X (t)inferior- YT). Evident, pentru orice moment t diferența lor Z(t) \u003d X (t) - Y (t) nu există nimic altceva decât numărul de aplicații din QS. Când liniile X (t) și YT) îmbina, nu există aplicații în sistem.
Luați în considerare o perioadă foarte mare de timp T(continuând mental graficul mult peste limitele desenului) și calculați pentru el numărul mediu de aplicații localizate în QS. Acesta va fi egal cu integrala funcției Z (t) pe acest interval împărțit la lungimea intervalului T:
L autoc. = . (19.9) cca
Dar această integrală nu este altceva decât zona figurii umbrite în Fig. 19.2. Să aruncăm o privire bună la această imagine. Figura este formată din dreptunghiuri, fiecare având o înălțime egală cu unul și o bază egală cu timpul petrecut în sistemul aplicației corespunzătoare (prima, a doua etc.). Denumiți aceste vremuri t 1, t 2, ... Adevărat, la sfârșitul decalajului T unele dreptunghiuri vor intra în forma umbrită nu complet, ci parțial, dar cu o cantitate suficient de mare T aceste lucruri mici nu vor juca un rol. Τᴀᴋᴎᴍ ᴏϬᴩᴀᴈᴏᴍ, putem presupune că
![]() (19.10)
(19.10)
unde suma se aplică tuturor cererilor primite în timp T.
Împărțiți partea dreaptă și stânga (.19.10) la lungimea intervalului T. Obținem, luând în considerare (19.9),
L autoc. \u003d. (19.11)
Împărțiți și înmulțiți partea dreaptă a lui (19.11) la intensitatea X:
L autoc. \u003d.
Dar amploarea Tλ nu este nimic altceva decât numărul mediu de cereri primite de-a lungul timpului ^ T. În cazul în care împărțim suma tuturor timpurilor t i pentru numărul mediu de cereri, atunci obținem timpul mediu de ședere al cererii în sistem W autoc. Asa de,
L autoc. \u003d λ W autoc. .
W autoc. \u003d. (19.12)
Aceasta este formula minunată a lui Little: pentru orice QS, pentru orice natură a fluxului de aplicații, pentru orice distribuție a timpului de serviciu, pentru orice disciplină de serviciu timpul mediu de rezidență al unei aplicații în sistem este egal cu numărul mediu de aplicații din sistem împărțit la intensitatea fluxului de aplicații.
În exact același mod, a doua formulă Little este derivată care raportează timpul mediu pe care aplicația a petrecut-o în coadă ^ W och și numărul mediu de aplicații din coadă L pct:
W och \u003d . (19.13)
Pentru ieșire, este suficient în locul liniei de jos din Fig. 19.2 preia funcția U (t) - numărul de aplicații care au plecat înainte t nu din sistem, ci din coadă (dacă aplicația care a intrat în sistem nu intră în coadă, ci merge imediat la serviciu, putem totuși să presupunem că este în coadă, dar este în timp zero).
Micile formule (19.12) și (19.13) joacă un rol important în teoria cozii. Din păcate, în majoritatea manualelor existente, aceste formule (dovedite în termeni generali relativ recent) nu sunt date 1)
§ 20. Cele mai simple sisteme de coadă și caracteristicile acestora
În această secțiune, avem în vedere unele dintre cele mai simple QS și derivăm expresii pentru caracteristicile lor (eficiență exponențială). În același timp, vom demonstra tehnicile metodologice de bază caracteristice teoriei elementare, Markovsk, a serviciului de masă. Nu vom urmări numărul de probe QS pentru care vor fi derivate expresii finale ale caracteristicilor; această carte nu este un ghid pentru teoria cozi (ghidurile speciale joacă un astfel de rol mult mai bine). Scopul nostru este să introducem cititorului câteva „mici trucuri” care să faciliteze parcurgerea teoriei serviciului de masă, care într-o serie de cărți disponibile (chiar pretinzând a fi populare) pot părea un set de exemple incoerente.
În această secțiune, vom considera că toate fluxurile de evenimente care transferă QS de la stat la stat sunt cele mai simple (fără a o specifica de fiecare dată special). Printre ele se va număra așa-numitul „flux de servicii”. Prin aceasta, desigur, este fluxul de aplicații deservite de un singur canal ocupat continuu. În acest thread, intervalul dintre evenimente, ca întotdeauna în firul cel mai simplu, are o distribuție exponențială (în multe manuale în schimb se spune: „timpul de serviciu este indicativ”, vom folosi acest termen în viitor).
1) Cartea populară oferă o derivare ușor diferită, comparativ cu cea de mai sus, derivată din formula Mică. În general, cunoașterea cu această carte („Conversația doi”) este utilă pentru o familiarizare inițială cu teoria cozii.
În această secțiune, distribuția exponențială a timpului de serviciu va fi asigurată, întrucât este întotdeauna pentru un sistem „cel mai simplu”.
Caracteristicile performanței QS luate în considerare vor fi introduse pe parcurs.
^ 1. p canal QS cu eșecuri (Problema Erlang). Aici vom lua în considerare una dintre primele timpuri, problemele „clasice” ale teoriei în coadă;
această problemă a apărut din nevoile practice ale telefoniei și a fost rezolvată la începutul secolului nostru de matematicianul danez Erlant. Sarcina este: p canale (linii de comunicare), care primește un flux de aplicații cu intensitate λ. Fluxul de serviciu are intensitatea μ (reciprocul timpului mediu de serviciu t despre). Găsiți probabilitățile finale ale statelor QS, precum și caracteristicile eficienței sale:
^ A - randament absolut, adică numărul mediu de aplicații servite pe unitatea de timp;
Q - randament relativ, adică ponderea medie a cererilor primite de către sistem;
^ P deschis - probabilitatea de eșec, adică faptul că cererea nu lasă QS-ul să nu fie difuzat;
k - Numărul mediu de canale ocupate.
Decizie. Stare de sistem ^ S (QS) vom număra în funcție de numărul de aplicații din sistem (în acest caz, acesta coincide cu numărul de canale ocupate):
S 0 - nu există aplicații în QS,
S 1 - există o aplicație în QS (un canal este ocupat, restul sunt gratuite),
S k - în QS este k aplicații ( k canalele sunt ocupate, restul sunt gratuite),
S n - în QS este p aplicații (toate n canale ocupate).
Graficul de stare al QS corespunde tiparului decesului în reproducere (Fig. 20.1). Marcăm acest grafic - punem în jos intensitatea fluxurilor de evenimente la săgeți. De S 0 in S 1 sistemul transferă fluxul de aplicații cu intensitatea λ (imediat ce aplicația ajunge, sistemul sare din S 0în S 1). Același flux de aplicații se traduce

sistem de la orice stânga la următoarea dreapta (vezi săgețile superioare din Fig. 20.1).
Puneți intensitatea săgeților inferioare. Fie ca sistemul să fie într-o stare ^ S 1 (un canal funcționează). Produce întreținere μ per unitate de timp. Ne-am pus jos la săgeată S 1 → S 0 intensitate μ. Acum imaginați-vă că sistemul este într-o stare S 2 (funcționează două canale). La ea mergi la S 1 este necesar ca fie primul canal, fie cel de-al doilea să fie terminat; intensitatea totală a fluxurilor lor de servicii este de 2μ; puneți-l la săgeata corespunzătoare. Fluxul total de servicii dat de cele trei canale are o intensitate de 3μ, k canale - kμ. Concentrăm aceste intensități la săgețile inferioare din Fig. 20.1.
Și acum, cunoscând toate intensitățile, vom folosi formulele gata (19.7), (19.8) pentru probabilitățile finale în schema morții și a reproducerii. Prin formula (19.8) obținem:

Membrii de descompunere ![]() vor fi coeficienții pentru p 0 în expresii pentru p 1
vor fi coeficienții pentru p 0 în expresii pentru p 1

Rețineți că în formulele (20.1), (20.2), intensitățile λ și μ nu sunt incluse separat, ci doar sub forma raportului λ / μ. Denota
λ / μ \u003d ρ (20,3)
{!LANG-5172231af78ba7a6382e31075da199f0!}
{!LANG-d14487848e7de7eaffd2cbce23adc8a4!}
{!LANG-148f2e1acb2ba035db75a4e2adbefd77!} ^ P deschis{!LANG-b975045c1c39d318096e3622dfafc29c!} p{!LANG-30bfab39ab56392d8fe1832e73a165b8!}
R{!LANG-c42986fce6ea1c0e2d5d575df3dbdd95!} r{!LANG-207661109ca8104d729dc179db70b14a!}
{!LANG-39a64c1a221b66f15d3dba0334a6905c!}
{!LANG-149a401180e089c540ddcf400f03112c!} P{!LANG-fbf5256df1e60fc2ad23f848dfe4d438!}
{!LANG-9f941e8153f56cef2b65ddcd1a8f9b94!} {!LANG-cb98e55b975db7c4496809bff4434ca7!}
{!LANG-b15ac8e2eb9eab5d6be20b1b882f30a3!} (20.8)
{!LANG-368b7be1f4b6abadb901cc910eb1d229!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-95b04a4e219e3d5d4715e463a29828d0!} p{!LANG-2f6694df7e1a15cd433e1a8b086f71d2!} {!LANG-5182a9263d72a5a3506d14eac41c3634!}
k = 0 · {!LANG-603f96592878d9d8b76f5e7bdc7a1cdc!}{!LANG-6abf9359d379f2b1477bc22933b1d0a9!} {!LANG-12547ca5d9ec8744beb2638ef74518f1!}{!LANG-7c8a43dd7e87b45f6a344115ced14ad4!} {!LANG-bfa699561009f68b044201573129440e!} · {!LANG-1e8e1e172975ffdb783ee5a7e1bd4167!}
{!LANG-d2850fd889238b68265e5318d51faecf!} r{!LANG-8a2acf526de364f85f3d301f0c327579!} {!LANG-9f37ba421f04a9e2de82be470f0b9fbd!}0, 1, ..., {!LANG-fd152bd328847f29282ac3d9ab298a5d!}{!LANG-55c6ba36a41e6574bd3c94930aa68e2f!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-c01f02cb3f23bd81191fbb147c16176c!} {!LANG-379991589a958b5295ff4ccb6fca25c3!}{!LANG-395c9ed5a920dcae3495229feec3a778!}
{!LANG-dfd32552b7cd08d0f6717c3a5de55e16!} (20.9)
{!LANG-694608f62c6ae440e78dbdd377a9b49e!}
{!LANG-263495c3fc2ba12d9d88a533d42f54a0!} ![]() (20.10)
(20.10)
{!LANG-5907eb1d234b199ab4c1b90645a43a52!}
{!LANG-62148b3cb29a4691a1ecf17dd6f53146!}
{!LANG-05786db4f3210f358244781520d8dadb!} n{!LANG-c4b646d6bc085bf4c82692afe0ebfa7e!} t{!LANG-4bfbae34badc6a08e39e6351a57466fc!} {!LANG-f53719ed51c82d011716ee6062a48f3e!}{!LANG-f8f7a54ca24a5d5a46b16afdfa0e2704!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-62d769f788f3f66d92be9f46c413e7e8!} p 0 = 1/13, p 1 = 3/13, p 2 = 9/26, {!LANG-0339bae4f833d9b7909a6cef834ddc74!} = 9/26 ≈ 0,346,
ȘI≈ 0,981, {!LANG-132bf2be3e39bd19ca8b930e92e955ad!} ≈ 0,654, P{!LANG-e20692c944c891f648a53d68951250d5!} {!LANG-7e5ac76aa9888547d4ef51dca6369471!} 1,96.
{!LANG-d30408ce0f810bafd35a94a224f8e05b!}
{!LANG-8976b06c826c787c440f68ce06c671d0!} {!LANG-af3f246e660b4f6ddb22e9d48910a87b!}{!LANG-6af1d40a103c5b20064d044077370398!} {!LANG-1ad471ec4e3014cea8317a6496210f28!}{!LANG-aca54b5cfaf82a5fd2afc9268bebec53!}
{!LANG-8e945b9ec1ce1e71096a83ae003798f2!}{!LANG-69a825959d05a8011fc628487ca9f2e5!}
{!LANG-2e5a67e405b70f21c1714f586e4f4949!} ; {!LANG-70e5d46723a8e1401b0bae87b48b845c!} t{!LANG-ac2a69e917ac9c75e934e1d2c04822bd!}
L autoc. - {!LANG-631f274228bf4b0552c73cede41d3487!}
W{!LANG-efed2f245b3832808d75164491f8c160!}
{!LANG-d86fd1731c5714c1fd124b611bb27255!}{!LANG-6806af3d5936fbbfb1a710ca3480ba36!}
W{!LANG-1f242b4ddcff9fce324999b884ea98d5!} - {!LANG-1b18bd4820b9118f4ab350136bdc2269!}
P{!LANG-638400b2e3c1086237064a630467ad37!} - {!LANG-a6ad472fc18200693a1e36e5ec1474a5!}
{!LANG-dc0b272ff8189963fc9a65379ce9a0d0!} ȘI{!LANG-0fbda163e1b9a81421e40aa7daac82cb!} {!LANG-68d2b09e3f3e77d20810ae80ae611922!}{!LANG-a5d1477788884fb3fdb9c231eb16b0e4!}
{!LANG-99910d2d35ff7fd7b0c10397f3fe2640!} {!LANG-8f9c190c7f381ea877b5dc19368cf76d!}{!LANG-63d9163a55865dda3f8fb2259efb3585!} {!LANG-5f4f8984d951cd3f252cc79358941f65!} 1.

{!LANG-59bffe77337deeb410c9e9a6650e9e2b!}
S 0 - {!LANG-f69cebf9147d696658129681c4747ee5!}
S{!LANG-516d5342ab04eb7f72d12a70e4f67ccf!}
S{!LANG-f9de9ffb8b3dc2446199d8ba6ae4fd4f!}
S{!LANG-caaea052e7659d41660198a7022673be!} k -{!LANG-c2115414470a17542d5e3de4a0482ae0!}
{!LANG-2b03b27c8c7e5e27ef8a920a2e291873!}
{!LANG-c7c928b5bdad14edfb4119b480822413!} {!LANG-49fe87a0ef9a0ef03c2a484e585da671!}{!LANG-a9be0a39b06c05e1fcc0a7ad46a7e6ee!}< 1), то финальные вероятности существуют, а при ρ ≥ 1 очередь при t{!LANG-e69651dc4d30df9ba5faac5492f74fe1!}
{!LANG-c1294930f46c4a65ef6642d72ddbdf3f!} {!LANG-03bcbb489b5137bd445d4007771167c1!}
p 0 = -1 =
{!LANG-f1f66ae998dd0538033cf50e6acb2d30!}
{!LANG-20d680f92b63768f9df9aac563be593d!}< 1 ряд сходится - это бесконечно убывающая геометрическая прогрессия со знаменателем р.
{!LANG-62148b3cb29a4691a1ecf17dd6f53146!}
{!LANG-4db7f2d4c2c98e9d23b6ac88204345a5!} {!LANG-3c892e826f6207cb81c721f2d6dc9a37!}{!LANG-0a9a4164dbf9ab3f66d3578eda37ba19!}<1). Теперь предположим, что это условие выполнено, и ρ <1. Суммируя прогрессию в (20.11), имеем
{!LANG-55c5295141e9ef8614deb8b3c1e54bd9!}
p{!LANG-1e79f803ca62dfb95c40b4da80d521b5!}
{!LANG-3c9dceacba4816a2b39e66df8f3414ae!} {!LANG-63d825862cae9d186c7109cabdb3a9e9!}{!LANG-859a6caee5e7711584c5407c81ea3598!}
p 1 = ρ {!LANG-eb2f621e0fcf680a3f6dc1d44e125b42!}{!LANG-dc5fb83bc1b8fcd70bbcdec0feba286e!} {!LANG-a87e235abb040ef4faf2787dd51bfa77!} ρ {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, ...,
{!LANG-43e16600b693f8829f0df8fccd7baed5!}
p 1{!LANG-a694387d17372b372fdff95313235d23!} {!LANG-6c3a9e29f9d1db53009c9ee217ee9cfc!}{!LANG-4430849fdddc74739c8b43b93b5d096f!} {!LANG-08f5cc28ea2ea53d4f7f150bc1186c43!}ρ {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-fbf873a07e72cb8713c4ca16495a7ddb!}
{!LANG-82332a2e512e427cb586e1fa4dce2c8a!} {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, p 1, ..., {!LANG-51b9ad8d5796b47ed8eb804798ef96fa!}{!LANG-0de2b4baac33cf96047720c05faa4087!}
{!LANG-62148b3cb29a4691a1ecf17dd6f53146!}
{!LANG-53cdcf10ec4e3092d21eb6def6f67853!} {!LANG-40ce6b5b87b6b8331cb8adff6e0057db!}{!LANG-c3401f303e49e4b51055200a00aebba1!}<1), самое вероятное число заявок в системе будет 0.
{!LANG-4dc7b0ddb9541b69e220c05e96bf0767!} {!LANG-d1505d3356afbdf681a44f474d1040df!}{!LANG-1cc5279815c41a0c3256027ccf6ae711!} {!LANG-c2bd13c15a5e5a51cc514e102bf43ae6!}{!LANG-2075bc466ab24af8d5b0cf7be9b33b77!} {!LANG-96cf96eb7554e8fe3d1cff4ca4717cca!}{!LANG-1f9b529df447b612d8727e9d89dbaa53!} {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, {!LANG-320b759f11097a8370746be14eff8f9f!}{!LANG-54fe951f32d819f56c0a131fd8922a6b!}
L{!LANG-80b2a0fa5dc2f399651975a0d61091cc!} {!LANG-76e5707a6016e35f45b3ee3ad66ff3fe!}{!LANG-08186adbb475a39613466c4b4bcb0549!} p{!LANG-360247dd1dde268ce73c3e9db20bdcd5!} p 2 +…+k · p{!LANG-56f6b96354546cff91c1721d2af5fd11!}
{!LANG-74aa6ca1d07b22f9d7ad7355342939d4!}
{!LANG-30e7c4f0c0b99e4258becc179c37318b!} {!LANG-ab21d4c6eaf9df2eb9e427aac3492b00!} (20.13):
L{!LANG-f4ba1c254801890a38992c4dd9c6b38a!} ![]()
{!LANG-0bd4e93cb6a0bec06eee9ff92f508bf4!}
L{!LANG-d497030f848a615a3dfc8cb7b7ccd251!}
{!LANG-7927aeaa95f2101120b54e7cc6ca555c!} kρ {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-88212d63111e7861cf45da6aeffb78f7!} {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-8e7cb03b3bb88aacb1896662ba4aad61!}
L{!LANG-d497030f848a615a3dfc8cb7b7ccd251!}
{!LANG-9e9533a0f1d5d878e428e55669cb2fe9!}
L{!LANG-42a3edc63ad9d551236f926a51bf27fe!}
{!LANG-68740bd2c23f0a3a149cb5631dda9ae4!}
{!LANG-02c2cb994796aadf821167ea94ca7f01!}
L{!LANG-2e360aa00dd84c40fa150b9731127453!}
{!LANG-6ba34ff0d7af0db3721d74e98074fabf!}
W{!LANG-fad40f093c4b9799d483123b87ba3798!}
{!LANG-cc5cefd86dc7aa91692c252bd82d3de3!} L{!LANG-7c054eca8451cc3fd13ca26d486ad855!} L{!LANG-f80bcdc4721f5c277dbe47c8602879c0!} L{!LANG-8fa32827dbd7ef0ef0a6f5586271c609!} R{!LANG-1cc688bacfc6d8962baf2bbc29fd001d!} R{!LANG-40f526779ebd97df9ce86f09454bc74d!} p 0{!LANG-3ddde5c852012da966b7331db4442c3b!} W{!LANG-372dd86017a0253cb2dc79e7cd2ca78c!} L{!LANG-142966e5177d5f956b79777af750d61f!} W{!LANG-f77fc6ee0d77256c861af00e0d3a8b97!} L{!LANG-b6d25a732ba1643612b3239d40ebee6b!} W{!LANG-1811b55900a790bffacca34dd55e2fd6!} L{!LANG-2a977325f7f2b8a70ed1237845a0f45c!} W{!LANG-997d1360023160944115b2ca040b9ef2!} și{!LANG-4d6a4a2a76c316f11bf61ff30d83aaec!} și.
{!LANG-aaa844408d5dfbd3d5aea374f64da27b!}{!LANG-e8a16f84277a94d1cdebc7aede338622!} n{!LANG-7bcb462a9a19909f6fc504b142a5b5ac!}
N<1. В случае если ρ/n{!LANG-0c3562fd109469714602c5b7c7faa937!}
{!LANG-bef4990289647528434add93b4d7180d!} n < 1 выполнено, и финальные вероятности существуют. Применяя все те же формулы (19.8), (19.7) для схемы гибели и размножения, найдем эти финальные вероятности. В выражении для p 0{!LANG-6d7ab1723841473bea3f27c9092f1366!} n{!LANG-c3598a83759b5394caa5b43a962c55ea!}
 (20.22)
(20.22)
{!LANG-1d1665bd58828c2a848a69e694fb2e47!} k{!LANG-66a183b12241c3b3f031e677639a708b!} L{!LANG-bba728b5a162706d9c846a53e37871af!} L{!LANG-2b154998e18cacf22be1627428d123ac!}
L och \u003d
{!LANG-184940bf3a21b13d29bff85a90dbe6fe!}
{!LANG-9fee7dc48708c838c5dc449c631b94c1!}
L och \u003d ![]() (20.23)
(20.23)
{!LANG-7457c841ba828dc76c40cdd8f75b4332!} {!LANG-8ce1a12a9fc4287a3b85ba79e1ed8957!}{!LANG-bd23e97d874ffb1621f3b60b593ddc38!}
L{!LANG-174cdc86b60f1ff7cd35b27c4c23a2d8!} L{!LANG-aaa42214e4b25401c2f26d4dfd8600e2!}
{!LANG-fbadf91611907d599faabb0df1aa4ae9!} L{!LANG-05de53229b760e5cf5f8ee9b1d2a28ac!} L{!LANG-83a0b28bf706ad8cc7cce09c6e35989b!} , {!LANG-e3706f87011aa0c9877b1975c15bd2f4!}
![]() (20.25)
(20.25)
{!LANG-2c22e9de50033b30b10e70930a7c14a2!}
{!LANG-62148b3cb29a4691a1ecf17dd6f53146!}
{!LANG-1d637ebdbbb8b7f02221e40433d6ab49!} {!LANG-6fb2b10fec9e4e3bc68de273d9be1a73!}{!LANG-9b609d30db63d9a058da55be95a5f56b!} {!LANG-090210d49625dd7aaece0552b72bca24!}{!LANG-93a0288fa027b2176d28c652b8dce6d0!} +
{!LANG-01bd2d069495da4d945ac4eae13a6015!} ȘI{!LANG-ca83deb3e790c3f40451a476b4ad6835!} {!LANG-1fbd942aa6137900ed07b65f7c9d5a08!}{!LANG-95037418d506a8e32b0347b6f056bc27!} ȘI{!LANG-a9810694ed1eedbe1102e8d80ed6d0a8!} {!LANG-6fb2b10fec9e4e3bc68de273d9be1a73!}{!LANG-1a59af1c5e4214806413c5b1bab0e5a4!}
{!LANG-dec1f4f7bb8074c3e0cf1da945a5b2ff!}
{!LANG-825cdf3ddb2ed81ba957409875cd6d2d!}<1, финальные вероятности существуют. По первой формуле (20.22) находим {!LANG-78a97dd5bd8d6cd9b0cd10a7a18e5c4f!}{!LANG-31bac04efdab1cda325cc0db31066b61!} W{!LANG-341a51072ca0113e87c78e9b2ccdb11b!}
{!LANG-d4ef5b996a3e11e7532a0eeb0f31fa6a!} . {!LANG-ef01456515d729c5fc1d4d78897194aa!}<1; финальные вероятности существуют. По формуле (20.20) находим среднюю длину очереди (к одному окошку) L{!LANG-0c145116fd05c0252525f2e772495e2a!}
{!LANG-99bf339dd1c51e88b2617aa0370831c8!} L{!LANG-07498a7b5c5a683c03ab2e66d44920ef!} W{!LANG-3522da79fedfc33caaf7fc388b9d64fd!}
{!LANG-78fd667e5a677f8c65684a6fa1d6ff4d!}
{!LANG-2eef793ace5bddc5ea98b8e1b0ae57b7!}
{!LANG-2bd10c0f36fc1d8c2e4f7b2fc7e3eecc!}
{!LANG-181956d0e1b3b1c6ad8cc31195210e70!}
{!LANG-bb0d9a8c62846d41838de6eef8b45269!}
{!LANG-bff26face3c1669d824411acca87b673!}{!LANG-23d81e18b3777f92f8d71b702309ddea!}
{!LANG-2460534e7b626f0b8837ed007ab286b5!}{!LANG-78932368f710f534920b67cf438a26e1!}
{!LANG-acb4c4d35e8b0a90bcfdd10f71013dd8!} t{!LANG-2959d19f36f842e05be2bdca9674e560!} S{!LANG-45f7b443bb06471512d139461d13ffce!} S{!LANG-9587ef234bb28c96b7f986e47f677150!} S{!LANG-b8f50b44a64cebf19bf98f1c0b259847!} S{!LANG-63a37140ba6ca52c6660769a03744cd8!} S{!LANG-6f9fdbff71ee4979312d0af3991c8c2e!} S{!LANG-dbf4ad266d5cbf583a5db0cc97091394!}

{!LANG-ce8415dbcbae42d06990c3d6be8a3948!}
{!LANG-f4a7c69ca0434df277193c88abd59504!}
{!LANG-914ebe8823d60b1a37e77011504b35fc!}{!LANG-8b556b0ef6dcd951a25cde57c6d157f2!}
![]()
{!LANG-a78650ab0175fccdb1900e3f8fc16450!}
{!LANG-2cd4027e2ea4ef9d11bdb6a48f267f72!}
{!LANG-91a2577fbb8387e98a0eb6e2166cf62b!}{!LANG-5652306bf38904a33b848cfb7d92e53c!}
{!LANG-d050e9c63a35ce7743a611da835b3ea2!}{!LANG-62b6f4358da17b3bc369bf020da5419c!}
{!LANG-12f5845b49901cd899aba2e26ca91963!}
{!LANG-a6383b5f1cc078aca09740ae133c1b29!}{!LANG-b717bb718b5223a04a529e6068384ebb!}
{!LANG-6a5d28244fc0c27a38711c032f6e4223!}
![]() .
.
{!LANG-8ce68c345289b5081140bb65599ba7b2!}
{!LANG-1f2d017c80f7e2b2ac171bd76d483c05!}
{!LANG-19411132206387790619ac3a854d6111!}
{!LANG-bff26face3c1669d824411acca87b673!}{!LANG-ee16a63b732561ac82656c8147a28274!} n{!LANG-f0306191479ac3ecdf658a4212bf45be!}
{!LANG-2460534e7b626f0b8837ed007ab286b5!}{!LANG-d8f31201d3616e859f1d2f79e8d99923!} t{!LANG-fb6ac3e8cad791d6b1794ff27f62a2cf!}
{!LANG-e6e7fac13bb5d58be8ad206bc41518ae!}{!LANG-d1e4549319c006e27d54c5343981057a!} S{!LANG-658e13f090615f91ff522b788f0caff0!}
S{!LANG-770d397a618494c6a23303cadf8fe5ef!}
S{!LANG-fe808b6d0a22d61a7be56ed4589c02e0!}
S{!LANG-bec8d26434dd0d1aafefa84750b83b41!}
S{!LANG-adbdc8e15b70a56f0d0a8b99d4327dca!} n{!LANG-6d257d5e95af73b4559238f6faf983d9!} n{!LANG-dc44d90ed506ca3674207add458a1f3b!}
{!LANG-056301f3028836db97d6de0b7fc8836b!}

{!LANG-6649118b626fb4d6ae13f2bf046f3762!}
{!LANG-3e3c8cdf160116d960be53abb16adc69!} S{!LANG-ac2e4580b68887051483e6e63ed720c4!} S{!LANG-4036287ccab1b4c345017a7ad741876e!} S{!LANG-b8f50b44a64cebf19bf98f1c0b259847!} S{!LANG-828342dff9b334edd4192aa892ceb702!} S{!LANG-ef9e470236ad8a680f95cd0ea993f919!} S{!LANG-812c89be265ad4215aa602ffa80bcd50!}
{!LANG-8063390688a90b5070eb3bb8a0ae090c!} S{!LANG-8a1612ab63b3ac8926b4ed5807825c5a!} S{!LANG-a4f339aa1aacad1ad682257bf0cdf9c0!} S{!LANG-5ae768d806d47272f250abe38762dec3!} S{!LANG-0827cbb91ebd30fb690600a908f94f6d!} S{!LANG-534717dc9fe881151dabe33331a826a1!}
{!LANG-6e5c8dfc4c71be2900ac07d97b903d9f!}
{!LANG-898a719a8d8eab6dfcbb54e57a7528d5!}{!LANG-e254ac1847095f3559782fca634be9f5!}{!LANG-e4d851cbfdc292a4954c1ac7b3182c3e!}:

unde n{!LANG-0e3b8448869d0dc3a1d73df0c63e0bfc!}
{!LANG-1ac01edf7bdb670019fb374e45e63a15!} S 0);

{!LANG-e3acaca24cf9ef4a8d9b37dda4a55485!}
{!LANG-86325dd5cf8cd0552922e0421306c57b!}
{!LANG-6656c93f5c799e8e0dc59bee0c6e1c00!}
{!LANG-9b0291deae518482a8162e8d15d0b86e!}
S{!LANG-6ce381c86b6eb9d9452d0bb0095f65c6!}
{!LANG-9813aa9af218389bf84b18567832f61a!} S{!LANG-6240b82baaaea1b7748a981de360b94c!}
![]()
{!LANG-9813aa9af218389bf84b18567832f61a!} S{!LANG-284a7ec5f0b1e1c422c7b6d9eded300c!}
![]()
{!LANG-ecc61fe22fed0a2c54ab23740ec7764c!}

{!LANG-bfd750d1e06f5e14a09091b3d696af7b!}

{!LANG-8e0b21e7a5b450f94d6fd74075e0c539!}
{!LANG-1ecfb62e2f3696f840e3b70de725e156!}{!LANG-a915cd75f7d48ba4e887143ce45862ae!}:

{!LANG-8a25d8a213f2a8416ce9aeea251f591d!}
{!LANG-034009ad14378a742e4c09f691498432!}

{!LANG-4a8cefeb76e8275608a11fd290adb364!}
{!LANG-cb9921b6a798226b75f455ea6452bb2a!}
{!LANG-16cea4e2b08e23215565f6ce02335c46!}
{!LANG-81151ff2372cef06b16f195f2be4061f!}
{!LANG-1f2c5e53d68596a06b6073817ea8e2f6!}
{!LANG-3b6a163a853a6d84110353f5402ae8db!}
{!LANG-5223202fedccb85aa7dea150950f1c82!}
{!LANG-a720724a35f8d0701cef08cdf553b9a8!}
{!LANG-3f3c38acfd240f5830c5dcf119b08ac9!}
{!LANG-0b3f464dc5016476b11db73005b599db!}
{!LANG-72632fe11e027df514868f2be5061639!}
{!LANG-22f2799d3ffeab9086ae4d520950be8c!}
{!LANG-e4406351daaf60713c5cdc863cfa7458!}
{!LANG-9b72be3ac9a5a75e5c23451dea9f1de6!}
{!LANG-8bef37d045a4767bb6bf927833cb694e!}
{!LANG-abc383024947f7ce52799353806ed625!}
{!LANG-5e3a3cc62c90bc41597bf67c9ea8a845!}
{!LANG-49b44991453451ffaafc27e85480446e!}
{!LANG-f6ed38b565afbae7d8f6015531211b5b!}
{!LANG-cd44b6fe2f1fc3e5a2d1776d54567ded!}
{!LANG-9c0024e04b6d08cbf5dae5e1093d7a1d!}
{!LANG-22387953b975a5172951f79bdd1f74d9!}
{!LANG-878ac8d037c5bed4aa08303165fa8cee!}
{!LANG-5a462a742c16c8076d1fa7d48dd3e321!}
{!LANG-97c22e2dbd07a09ff5aa8106ab38aafe!}
{!LANG-b1f8d1e04cc9d4faad1c9e3dc9acc370!}
{!LANG-198b9089fcc62a529b50f29d161ab782!}
{!LANG-0600bc0eb97b98f3d9e9bce04394bdc6!}
2) alegerea formulelor în conformitate cu tipul QS;
3) soluția problemei;
4) formularea concluziilor asupra problemei.
{!LANG-86ef49f2b939d81d2a570144598904e1!}
{!LANG-a70999fef740479cb979e40c620e8021!}

{!LANG-b155f56f6b6e27ff98d554ad45030a60!} S 1 , S 2 {!LANG-7c0e2a1add1277b010b0b373bd4ddc1a!}{!LANG-cbe565d81d65e429d1b545bbbaef5c50!} (S 0 , S{!LANG-bbade86e744fd2546b0d74d12e53bbc1!}
{!LANG-0d6cd78c7c8b57c171510c105b6ba145!}
{!LANG-f67f396606ead3cced7de4f2caa14ae5!} S{!LANG-ce12db41d8ddaec92d1cf6bfd7a5530e!}
{!LANG-9ba190bcbe3852444ee150be01970b5f!}
{!LANG-847402f38139c35ca9cbd4e9e021bcb4!} S 0 avem:
![]() (19.1)
(19.1)
Pentru a doua stare S 1:
În virtutea (19.1), ultima egalitate se reduce la formă
![]()
![]()
![]()
unde k{!LANG-da9b8fd09f666128223fd1ae4632b899!} p. Deci, probabilitățile finale p 0, p 1,..., p n satisfac ecuațiile
 (19.2)
(19.2)
{!LANG-3d90899e060dc18d08f05b96581d6f38!}
p 0 + p 1 + p 2 +…+ p n \u003d 1. (19,3)
{!LANG-dfb52cc2b9273453f366c656b642cd74!} p 1 prin r 0 :
p 1 = p 0. (19.4)
Din a doua, luând în considerare (19.4), obținem:
![]() (19.5)
(19.5)
{!LANG-35067351f25b02bec76cbd52106883fe!}
![]() (19.6)
(19.6)
și, în general, pentru oricare k (de la 1 la n):
![]() (19.7)
(19.7)
{!LANG-e30f0a4c7f7be6d77785d08bfb014181!} S{!LANG-2fd93fd016cf63abb332f3c830c14ef1!} S k).
{!LANG-989f18f37445ab0f67ebf36573d56a2e!} r 0 , p 1 , ..., p n exprimat prin una dintre ele ( r 0). Înlocuim aceste expresii în condiția de normalizare (19.3). Primim, scoatem paranteza r 0:
de aici obținem expresia pentru r 0 :
(am ridicat paranteza la puterea de -1, pentru a nu scrie fracții cu două punți). Toate celelalte probabilități sunt exprimate în termeni de r{!LANG-e014b788c9699a3e36f2ef03aee495e1!} r{!LANG-14a3d05052afe295c5904b54785d3377!} r 0 , {!LANG-2e0480315178daebff375eb9423f373e!}
Formulele obținute sunt foarte utile în rezolvarea celor mai simple probleme ale teoriei de la coadă.
{!LANG-2454096472c334ec25128889cad2dd6c!}
{!LANG-18a921eccc43065f949584e0832061fd!} L un sistem localizat în sistemul de coadă (de exemplu, deservit sau în linie) și timpul mediu în care o aplicație rămâne în sistem W autoc.
{!LANG-941033e9f44a2d3c4882a0abbcd8dbee!}
Denota: {!LANG-02029d6f8468784c55fc266c02d2f51d!} numărul de aplicații care au ajuns la QS înainte t. Y(t) — numărul de aplicații părăsite QS

până în momentul în care t.{!LANG-3c6f2baaa08c1ad6d53c50cc882f5aae!} (X(t)) și părăsirea aplicațiilor (YT)). Tipul funcției X (t) și Y (t){!LANG-fbc45a7361e2a63691b8cc1be10921a5!} X (t){!LANG-b20b9b2a86cc531caf48b4211f4067ed!} YT). Evident, pentru orice moment t diferența lor Z(t){!LANG-1cf0dcd4ccf7a18783f4ef40cfd37dac!} nu există nimic altceva decât numărul de aplicații din QS. Când liniile X (t) și YT) îmbina, nu există aplicații în sistem.
Luați în considerare o perioadă foarte mare de timp T(continuând mental graficul mult peste limitele desenului) și calculați pentru el numărul mediu de aplicații localizate în QS. Acesta va fi egal cu integrala funcției Z (t){!LANG-5c0f5a725b7972b2e16aa444154d3da3!} T:
L autoc. = . (19.9) cca
{!LANG-66b7d97dc4f497e19888eebd48b23a92!} t 1, t 2, ... Adevărat, la sfârșitul decalajului T unele dreptunghiuri vor intra în forma umbrită nu complet, ci parțial, dar cu o cantitate suficient de mare T{!LANG-574c81960a3a6b3303a726d70adbb030!}
![]() (19.10)
(19.10)
{!LANG-958ded2a64c2e649ba462961b2c25d4b!} T.
Împărțiți partea dreaptă și stânga (.19.10) la lungimea intervalului T. Obținem, luând în considerare (19.9),
L autoc. \u003d. (19.11)
Împărțiți și înmulțiți partea dreaptă a lui (19.11) la intensitatea X:
L autoc. \u003d.
Dar amploarea Tλ nu este nimic altceva decât numărul mediu de cereri primite de-a lungul timpului ^ T.{!LANG-b597497df23d438d7e74e8d583aaab6b!} t i pentru numărul mediu de cereri, atunci obținem timpul mediu de ședere al cererii în sistem W autoc. Asa de,
L autoc. \u003d λ W autoc. .
W autoc. \u003d. (19.12)
{!LANG-f78c618b8894eb566b9613472a66f2d2!} {!LANG-60490afcffa9e21d41716901e37aefb6!}
În exact același mod, a doua formulă Little este derivată care raportează timpul mediu pe care aplicația a petrecut-o în coadă ^ W och și numărul mediu de aplicații din coadă L pct:
W och \u003d . (19.13)
Pentru ieșire, este suficient în locul liniei de jos din Fig. 19.2 preia funcția U (t){!LANG-32e46f749a1f54714786244fe43aaf5a!} t{!LANG-5da52da76c8ba3f3aa125e2313741d1b!}
Micile formule (19.12) și (19.13) joacă un rol important în teoria cozii. Din păcate, în majoritatea manualelor existente, aceste formule (dovedite în termeni generali relativ recent) nu sunt date 1)
{!LANG-f469dab58ecded9fa8bf8bcdb377733c!}
{!LANG-998ecfee1bb3c58735bc69627cc9f7be!}
{!LANG-ef6769050c2d2ad67ef48aef2986fc40!}
{!LANG-ddd10a04a02d53557ea2281d4f8c3196!}
{!LANG-a68f0c2cb56df09bb6032c2f16ffd6eb!}
{!LANG-4efb079fcce25ecc5e953edc8a90a8a6!}
Caracteristicile performanței QS luate în considerare vor fi introduse pe parcurs.
1. p{!LANG-a8d73966b59ad742d2a3e8a6f65b0fda!}{!LANG-42b02b8e75a6182f14227951382df68f!} p canale (linii de comunicare), care primește un flux de aplicații cu intensitate λ. Fluxul de serviciu are intensitatea μ (reciprocul timpului mediu de serviciu t{!LANG-ed16e1d3269a314419749cc342c98fc1!}
{!LANG-eaa0d598cded990340ca310383d7487a!}
{!LANG-f6b71c37dd6033e7869127a3b0a13537!} randament absolut, adică numărul mediu de aplicații servite pe unitatea de timp;
{!LANG-01e4059f46ece9fc28f51eae8d348f26!} randament relativ, adică ponderea medie a cererilor primite de către sistem;
^ P deschis{!LANG-9d61dd8b45789b68a425518fd52b1a82!}
{!LANG-a54e4ccf6836ec7274c344b8712254d1!} Numărul mediu de canale ocupate.
Decizie. Stare de sistem ^ S (QS) vom număra în funcție de numărul de aplicații din sistem (în acest caz, acesta coincide cu numărul de canale ocupate):
{!LANG-fa177d6cf18eef71e92459561ace0d15!} nu există aplicații în QS,
{!LANG-b8f3dad9df04466175ad26aa17c2e02b!} există o aplicație în QS (un canal este ocupat, restul sunt gratuite),
{!LANG-da402324f9440d787f0d20698134f0d4!} în QS este k aplicații ( k canalele sunt ocupate, restul sunt gratuite),
{!LANG-50e13c4adfb72290316cd07329c6f012!} în QS este p{!LANG-6ead226f2dd7501c453baa2147d628ea!} n canale ocupate).
{!LANG-8ec925cd2f7995da2033ba961ff1cb48!} S 0 in S 1 sistemul transferă fluxul de aplicații cu intensitatea λ (imediat ce aplicația ajunge, sistemul sare din S 0în S 1).{!LANG-de916589001bd83e4477f8269a0d5407!}

Puneți intensitatea săgeților inferioare. Fie ca sistemul să fie într-o stare ^ S 1 (un canal funcționează). Produce întreținere μ per unitate de timp. Ne-am pus jos la săgeată S 1 → S 0 intensitate μ. Acum imaginați-vă că sistemul este într-o stare S 2 (funcționează două canale). La ea mergi la S 1 este necesar ca fie primul canal, fie cel de-al doilea să fie terminat; intensitatea totală a fluxurilor lor de servicii este de 2μ; puneți-l la săgeata corespunzătoare. Fluxul total de servicii dat de cele trei canale are o intensitate de 3μ, k{!LANG-7296ce8cd5f148c2377d5dcd66015680!} kμ. Concentrăm aceste intensități la săgețile inferioare din Fig. 20.1.
{!LANG-20003da01b98259af376f70cdc11b26e!}
{!LANG-fcb00feb5f74d6d90c8acefb95d23960!}

Membrii de descompunere ![]() vor fi coeficienții pentru p 0 în expresii pentru p 1
vor fi coeficienții pentru p 0 în expresii pentru p 1

Rețineți că în formulele (20.1), (20.2), intensitățile λ și μ nu sunt incluse separat, ci doar sub forma raportului λ / μ. Denota
{!LANG-7c5411d51b6ab07983c6eef4af5552de!}
{!LANG-bf2994b6876c05be3203f232f18f9c98!}
{!LANG-19d5f231690bf4420eaa69ddecf39bdd!}
{!LANG-74c8faa190fc203303a5a4478d0fae57!} ^ P deschis{!LANG-3ed3ead09438e7dc6df981351e3afa2b!} p{!LANG-30bfab39ab56392d8fe1832e73a165b8!}
R{!LANG-c42986fce6ea1c0e2d5d575df3dbdd95!} r{!LANG-207661109ca8104d729dc179db70b14a!}
{!LANG-8254bfef9fa52ea187fff22fb155ed1a!}
{!LANG-32ccdb8e109515852737d84b49b7720c!} P{!LANG-fbf5256df1e60fc2ad23f848dfe4d438!}
{!LANG-9f941e8153f56cef2b65ddcd1a8f9b94!} {!LANG-cb98e55b975db7c4496809bff4434ca7!}
{!LANG-b15ac8e2eb9eab5d6be20b1b882f30a3!} (20.8)
{!LANG-368b7be1f4b6abadb901cc910eb1d229!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-28211b06caa8ff4dc493bbb7513e32b4!} p{!LANG-2f6694df7e1a15cd433e1a8b086f71d2!} {!LANG-5182a9263d72a5a3506d14eac41c3634!}
k = 0 · {!LANG-603f96592878d9d8b76f5e7bdc7a1cdc!}{!LANG-6abf9359d379f2b1477bc22933b1d0a9!} {!LANG-12547ca5d9ec8744beb2638ef74518f1!}{!LANG-7c8a43dd7e87b45f6a344115ced14ad4!} {!LANG-bfa699561009f68b044201573129440e!} · {!LANG-1e8e1e172975ffdb783ee5a7e1bd4167!}
{!LANG-d2850fd889238b68265e5318d51faecf!} r{!LANG-8a2acf526de364f85f3d301f0c327579!} {!LANG-9f37ba421f04a9e2de82be470f0b9fbd!}0, 1, ..., {!LANG-fd152bd328847f29282ac3d9ab298a5d!}{!LANG-55c6ba36a41e6574bd3c94930aa68e2f!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-7ac0e78b6df7f9734e0c69055713ef78!} {!LANG-379991589a958b5295ff4ccb6fca25c3!}{!LANG-d07c8b2d96bc863f4a2cf04f72599bab!}
{!LANG-dfd32552b7cd08d0f6717c3a5de55e16!} (20.9)
{!LANG-694608f62c6ae440e78dbdd377a9b49e!}
{!LANG-263495c3fc2ba12d9d88a533d42f54a0!} ![]() (20.10)
(20.10)
{!LANG-8bf124b3c005722ae3ae32b753a53573!} n{!LANG-c4b646d6bc085bf4c82692afe0ebfa7e!} t{!LANG-1e0b29f8c4655d3828616e9545670ea8!} {!LANG-f53719ed51c82d011716ee6062a48f3e!}{!LANG-f8f7a54ca24a5d5a46b16afdfa0e2704!} {!LANG-672b18c716840a8384a8b143e6e90459!}{!LANG-62d769f788f3f66d92be9f46c413e7e8!} p 0 = 1/13, p 1 = 3/13, p 2 = 9/26, {!LANG-0339bae4f833d9b7909a6cef834ddc74!} = 9/26 ≈ 0,346,
ȘI≈ 0,981, {!LANG-132bf2be3e39bd19ca8b930e92e955ad!} ≈ 0,654, P{!LANG-e20692c944c891f648a53d68951250d5!} {!LANG-7e5ac76aa9888547d4ef51dca6369471!} 1,96.
{!LANG-e5e2dad94b309dda0f4c270c07d641d2!}
{!LANG-8976b06c826c787c440f68ce06c671d0!} {!LANG-af3f246e660b4f6ddb22e9d48910a87b!}{!LANG-5cdc608505cc47bf31632acc6c51bb16!} {!LANG-1ad471ec4e3014cea8317a6496210f28!}{!LANG-cd4fe2340d3732709c396810803f96bf!}
{!LANG-a50114cb7978904adebf99326423180b!}
{!LANG-eaaf0e936691f00b40f6d1d1146ab233!}
{!LANG-f1b99b459ece9ec04ac397a94653b381!}
{!LANG-87ba9e0fbdb63bd70046556a9b7a0a7a!} ; {!LANG-70e5d46723a8e1401b0bae87b48b845c!} t{!LANG-e359060f019ccd8a0c774ebe3db72cca!}
{!LANG-ce9c08ffabdb827ae05f3ef86ac8dfa9!}
L autoc. — {!LANG-631f274228bf4b0552c73cede41d3487!}
W{!LANG-6e0c97ba4c2332c5989983517568418b!}
{!LANG-d86fd1731c5714c1fd124b611bb27255!}{!LANG-5312f2018aac491a428b1f28bd0d902d!}
W{!LANG-1f242b4ddcff9fce324999b884ea98d5!} — {!LANG-1b18bd4820b9118f4ab350136bdc2269!}
P{!LANG-638400b2e3c1086237064a630467ad37!} — {!LANG-a6ad472fc18200693a1e36e5ec1474a5!}
{!LANG-dc0b272ff8189963fc9a65379ce9a0d0!} ȘI{!LANG-0fbda163e1b9a81421e40aa7daac82cb!} {!LANG-68d2b09e3f3e77d20810ae80ae611922!}{!LANG-3202f2254e5276f893f59fdf88ed8da1!}
{!LANG-65a39f17fc86dcf1d717b3b15627459c!} {!LANG-8f9c190c7f381ea877b5dc19368cf76d!}{!LANG-1605d67d9f0d4427a3286e3f30c306a5!} {!LANG-5f4f8984d951cd3f252cc79358941f65!} 1.

{!LANG-18027336f7b0cbcb8d4ab8f7cafa2ca4!}
S 0 — {!LANG-f69cebf9147d696658129681c4747ee5!}
S{!LANG-586369b153a5841cb00acdeca1fbe7ba!}
S{!LANG-ae4d8a79c4442051580e81273327f429!}
S{!LANG-fac05bcfe0d70baef33c56cc84b1b979!} {!LANG-a54e4ccf6836ec7274c344b8712254d1!}{!LANG-c2115414470a17542d5e3de4a0482ae0!}
{!LANG-c212b2c68c016daaf979340f36df2532!}
{!LANG-ecc34484eda8f8243de5db5a2164272b!} {!LANG-49fe87a0ef9a0ef03c2a484e585da671!}{!LANG-f1fdb5499b8978452ee79906befb1f38!}< 1), то финальные вероятности существуют, а при ρ ≥ 1 очередь при t{!LANG-e3dd25f2ad0e5b669df4b45772df6c99!}
{!LANG-36e2c90a40af0bde31fe4a77cf9e57f6!}
{!LANG-9a9a863db835f6577d614b0e23af4cb3!}
{!LANG-e3cacbcd883b1f33858a9a3ba4822394!} {!LANG-03bcbb489b5137bd445d4007771167c1!}
p{!LANG-d0c1f45e25ac38ed89f605fa54a1ff99!}
{!LANG-20d680f92b63768f9df9aac563be593d!}< 1 ряд сходится — это бесконечно убывающая геометрическая прогрессия со знаменателем р. При р ≥ 1 ряд расходится (что является косвенным, хотя и не строгим доказательством того, что финальные вероятности состояний {!LANG-3c892e826f6207cb81c721f2d6dc9a37!}{!LANG-0a9a4164dbf9ab3f66d3578eda37ba19!}<1).
{!LANG-6736b05ff0d281c03d5e7308fa985c43!}
p{!LANG-1e79f803ca62dfb95c40b4da80d521b5!}
{!LANG-3c9dceacba4816a2b39e66df8f3414ae!} {!LANG-63d825862cae9d186c7109cabdb3a9e9!}{!LANG-859a6caee5e7711584c5407c81ea3598!}
p 1 = ρ {!LANG-eb2f621e0fcf680a3f6dc1d44e125b42!}{!LANG-dc5fb83bc1b8fcd70bbcdec0feba286e!} {!LANG-a87e235abb040ef4faf2787dd51bfa77!} ρ {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, ...,
{!LANG-cc6cb6a9eacb75e7adac4ca2b9d1f7be!}
p 1{!LANG-a694387d17372b372fdff95313235d23!} {!LANG-6c3a9e29f9d1db53009c9ee217ee9cfc!}{!LANG-4430849fdddc74739c8b43b93b5d096f!} {!LANG-08f5cc28ea2ea53d4f7f150bc1186c43!}ρ {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-fbf873a07e72cb8713c4ca16495a7ddb!}
{!LANG-82332a2e512e427cb586e1fa4dce2c8a!} {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, p 1, ..., {!LANG-51b9ad8d5796b47ed8eb804798ef96fa!}{!LANG-24a77eaaa279214825395bd1d5bad7f1!} {!LANG-3c46e32436b5cce7143fbcfc79e5b3ff!}{!LANG-09fb01b73be5fc01d95e807a7fa1f716!}<1), самое вероятное число заявок в системе будет 0.
{!LANG-4dc7b0ddb9541b69e220c05e96bf0767!} {!LANG-d1505d3356afbdf681a44f474d1040df!}{!LANG-1cc5279815c41a0c3256027ccf6ae711!} {!LANG-503a280c4b8217c1caf4f3d70982e7c1!}{!LANG-3d5a05da9cbb7b2924b6a0e5f5bd0181!} {!LANG-96cf96eb7554e8fe3d1cff4ca4717cca!}{!LANG-1f9b529df447b612d8727e9d89dbaa53!} {!LANG-20f9e0868ba44a28d8e20178e0987a6c!}, {!LANG-320b759f11097a8370746be14eff8f9f!}{!LANG-54fe951f32d819f56c0a131fd8922a6b!}
L{!LANG-d0a6613387de3ce59ab96e4bffc2e546!} {!LANG-76e5707a6016e35f45b3ee3ad66ff3fe!}1 ? p 1 + 2 ? p 2 +…+k ? p{!LANG-56f6b96354546cff91c1721d2af5fd11!}
{!LANG-5ee60ab7bce8e94c198258d190d535a1!}
{!LANG-30e7c4f0c0b99e4258becc179c37318b!} {!LANG-ab21d4c6eaf9df2eb9e427aac3492b00!} (20.13):
L{!LANG-f4ba1c254801890a38992c4dd9c6b38a!} ![]()
{!LANG-0bd4e93cb6a0bec06eee9ff92f508bf4!}
L{!LANG-d497030f848a615a3dfc8cb7b7ccd251!}
{!LANG-d6e3c346e7cd584b18793cdf620d42db!} kρ {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-88212d63111e7861cf45da6aeffb78f7!} {!LANG-b5b78ea4a4ded2d6d906b6a055958844!}{!LANG-8e7cb03b3bb88aacb1896662ba4aad61!}
L{!LANG-d497030f848a615a3dfc8cb7b7ccd251!}
{!LANG-9e9533a0f1d5d878e428e55669cb2fe9!}
L{!LANG-42a3edc63ad9d551236f926a51bf27fe!}
{!LANG-bfc7fcf7aad4ead51d460532f136f34e!}
{!LANG-a2662b68a4251a5e9177d18dca157f87!}
L{!LANG-2e360aa00dd84c40fa150b9731127453!}
{!LANG-6ba34ff0d7af0db3721d74e98074fabf!}
W{!LANG-fad40f093c4b9799d483123b87ba3798!}
{!LANG-cc5cefd86dc7aa91692c252bd82d3de3!} L{!LANG-7c054eca8451cc3fd13ca26d486ad855!} L{!LANG-f80bcdc4721f5c277dbe47c8602879c0!} L{!LANG-a819144ff9b0f8d43225342b55883af3!}
{!LANG-6846212d56b5025ca0808acc67c4ef46!} R{!LANG-1cc688bacfc6d8962baf2bbc29fd001d!} R{!LANG-40f526779ebd97df9ce86f09454bc74d!} p 0{!LANG-e3d1f6bbca133bb0830bb7c41f3384f7!}
R{!LANG-f79f3fcfb053ffeff142e949c5abe789!} r{!LANG-0663857524acf3ee98549ea567f2fdc1!}
{!LANG-b52388446c0ccda36a09a5a3c7add163!}
{!LANG-ed345f381420f7de11b2d04e438c41b1!}{!LANG-ccd151977dd4f5dbcebc7a675d3d96a6!}
L och \u003d L{!LANG-fb209c0075cf4216268f6187ad50e852!}
{!LANG-113a1c41ff8566ef9783f4575fba332f!}
L{!LANG-5336cbaa00c2d35a23cc357f03b29f61!}
{!LANG-3b8d0a814d4f54ca54fda7c770b0c727!}
![]() (20.21)
(20.21)
{!LANG-247d0c8042af0e8bb65ac0c85286bfd6!}
{!LANG-5d3dbb62591ea638b44ab9d8a9a4ae8b!}
{!LANG-3ca1ad92087e7bc4d5f47d4f887ef181!} {!LANG-8204cb5c0ef4e5ecbe266ea27608055d!}{!LANG-f69c65d7a752ecffb1d63e52a6015fac!}
{!LANG-5c0fa7737f8dbb12a85d3b6fb061ffd7!} l{!LANG-518c4e0063975d5651e303de1be5cc03!} W{!LANG-02779dc209a1693a411508e6ccecf277!} L{!LANG-b8bda232060ea6dd765ce680fc855ced!} W{!LANG-9c2ecb0f3a4c110967d2ce9e33b8542c!} L{!LANG-2d557b8293a6543d7c59bd403ffb455c!} W{!LANG-9d93dfd988a4c591b6fbe8293a54a9e1!}
{!LANG-92facfb8a729e78ddb344f27cc3fb0cc!} L{!LANG-142966e5177d5f956b79777af750d61f!} W{!LANG-f77fc6ee0d77256c861af00e0d3a8b97!} L{!LANG-b6d25a732ba1643612b3239d40ebee6b!} W{!LANG-1811b55900a790bffacca34dd55e2fd6!} L{!LANG-2a977325f7f2b8a70ed1237845a0f45c!} W{!LANG-997d1360023160944115b2ca040b9ef2!} și{!LANG-4d6a4a2a76c316f11bf61ff30d83aaec!} și.
{!LANG-1ed560c66766dbdf8a041306e43e1e1b!}
{!LANG-e8a16f84277a94d1cdebc7aede338622!} n{!LANG-6f382afbd30a2aafe1963872c3f9ea89!}
{!LANG-bb09798dec1de8bd2831d5c27c4516be!}
{!LANG-d12a26f4337dbca3b834678f03e5b462!} n{!LANG-93e6d584aeefd2588aa39f27d19f92f6!}
{!LANG-bef4990289647528434add93b4d7180d!} n < 1 выполнено, и финальные вероятности существуют. Применяя все те же формулы (19.8), (19.7) для схемы гибели и размножения, найдем эти финальные вероятности. В выражении для p 0{!LANG-f2b57505b9c835b3df630b6eda4a224f!} n{!LANG-c3598a83759b5394caa5b43a962c55ea!}
 (20.22)
(20.22)
{!LANG-2a4247b0a3446ee5101f0aa27e627dfd!} k{!LANG-75f7e28d156a6a26a485484bed46f638!} L{!LANG-bba728b5a162706d9c846a53e37871af!} L{!LANG-2b154998e18cacf22be1627428d123ac!}
L och \u003d
{!LANG-184940bf3a21b13d29bff85a90dbe6fe!}
{!LANG-9fee7dc48708c838c5dc449c631b94c1!}
L och \u003d ![]() (20.23)
(20.23)
{!LANG-39d9f200f68fbd0350087d9860db2676!} {!LANG-8ce1a12a9fc4287a3b85ba79e1ed8957!}{!LANG-bd23e97d874ffb1621f3b60b593ddc38!}
L{!LANG-174cdc86b60f1ff7cd35b27c4c23a2d8!} L{!LANG-aaa42214e4b25401c2f26d4dfd8600e2!}
{!LANG-fbadf91611907d599faabb0df1aa4ae9!} L{!LANG-05de53229b760e5cf5f8ee9b1d2a28ac!} L{!LANG-83a0b28bf706ad8cc7cce09c6e35989b!} , {!LANG-e3706f87011aa0c9877b1975c15bd2f4!}
![]() (20.25)
(20.25)
{!LANG-be63bc6f33b2b470f3986962c7fcf581!} {!LANG-6fb2b10fec9e4e3bc68de273d9be1a73!}{!LANG-9b609d30db63d9a058da55be95a5f56b!} {!LANG-090210d49625dd7aaece0552b72bca24!}{!LANG-93a0288fa027b2176d28c652b8dce6d0!} + {!LANG-e3764fb642ff2499190dc36ebe65cd15!}
{!LANG-472e32ca54539520cfaabfb11e19c17a!} ȘI{!LANG-ca83deb3e790c3f40451a476b4ad6835!} {!LANG-1fbd942aa6137900ed07b65f7c9d5a08!}{!LANG-3929906b50127268ee7e5981ea54ed2c!} ȘI{!LANG-1b92581cf64e037583c5e56ca2e63114!} {!LANG-6fb2b10fec9e4e3bc68de273d9be1a73!}{!LANG-62a0f51ba030815923199f2942e4e1ec!}
{!LANG-6c844e915870a6c99d0d523f2edc9371!}
{!LANG-825cdf3ddb2ed81ba957409875cd6d2d!}<1, финальные вероятности существуют. По первой формуле (20.22) находим {!LANG-78a97dd5bd8d6cd9b0cd10a7a18e5c4f!}{!LANG-31bac04efdab1cda325cc0db31066b61!} W{!LANG-341a51072ca0113e87c78e9b2ccdb11b!}
{!LANG-d4ef5b996a3e11e7532a0eeb0f31fa6a!} . {!LANG-ef01456515d729c5fc1d4d78897194aa!}<1; финальные вероятности существуют. По формуле (20.20) находим среднюю длину очереди (к одному окошку) L{!LANG-0c145116fd05c0252525f2e772495e2a!}
{!LANG-99bf339dd1c51e88b2617aa0370831c8!} L{!LANG-07498a7b5c5a683c03ab2e66d44920ef!} W{!LANG-3522da79fedfc33caaf7fc388b9d64fd!}
{!LANG-78fd667e5a677f8c65684a6fa1d6ff4d!}
{!LANG-ef497310459ff71e79421a73d2f37f29!} {!LANG-1ad471ec4e3014cea8317a6496210f28!}{!LANG-25509073bda93ac3725b5bf0c322a13f!} {!LANG-1fbd942aa6137900ed07b65f7c9d5a08!}{!LANG-b0b213337c220b61baaae9e0e2bcbf8b!}
{!LANG-45fd9632ddb68f6f680d6bfbc704ef0e!} , {!LANG-f6c6f062cc917759d739254f760dfd79!}
{!LANG-5a00f895e4101b2eeb9090057fd5b0e1!} , {!LANG-1371d340897816ab4c936156e6ef2358!}
{!LANG-1d6afd541600be3d65c0e974745ed667!}
{!LANG-c38fac6657310c0370ad8f098ddfd9b0!}
{!LANG-cfb81157fe97bcab7d82a39795c0b747!}
{!LANG-f431e1fb07fe1a297feccf4c8415dc95!}
{!LANG-c519c45df4c5051f128c8f2e7522b118!}
{!LANG-39454352c6835795e0a789a5563f3a0b!}{!LANG-073fa99cae80d0dbd71abd4e7626c131!} {!LANG-11194a930d666cf255acbc5ee04f50c7!}{!LANG-545a1b57bb0dc0e4fd85fce9dd91f2c7!}
{!LANG-140f5ef22949fb6df48da3e705b0330d!} R{!LANG-21da603f7dcfec3db70ac0b00c5744c1!} {!LANG-1ad471ec4e3014cea8317a6496210f28!}{!LANG-5bc9ccbbe9d00b1619218d56e52e5618!} R{!LANG-120c8442c002ec3f2e69fecb4e04d2cc!} L{!LANG-a8555ca778cb537a59497b82882ddca0!} L{!LANG-669f41b1915f9865921bfe7b9c7ab6dd!} , {!LANG-ffc3188b13c156d5f357cf9db7d828fc!} W{!LANG-1f242b4ddcff9fce324999b884ea98d5!} , {!LANG-7dcf3d74c9cfb6c6a667b9b039e38e03!} W{!LANG-44a7789ca6d44166e11a75942fa1cbc6!}
{!LANG-d7e515a9783f29066d34551986aa5ea6!} m{!LANG-991dc43eb6a80fda919234110f256f37!}{!LANG-635c4ceb97007cd2224ca35107c90ea4!} {!LANG-537ac3fd61e64b26ee8f05ad7d15aafa!}{!LANG-d473c7e7da982ce5f2ecb6213b7b8369!} . {!LANG-8c048541d009d0bdf3990086d4b13c40!}
{!LANG-73949760875036533c765bf7192be931!} t{!LANG-547407fe161230fb1dafbd5a5797e779!} k{!LANG-60048facbca2860a698d44cdff4c841d!} k{!LANG-d796e27bd945596c453a8daaffbd5be0!}
{!LANG-2dc5ee1d66cf4468366cafa93a186767!} t{!LANG-4b9c65fd13c7986303bec88ff038ef59!}